MPI topic: Communicators
Experimental html version of Parallel Programming in MPI, OpenMP, and PETSc by Victor Eijkhout. download the textbook at https:/theartofhpc.com/pcse
7.2 : Duplicating communicators
7.2.1 : Communicator comparing
7.2.2 : Communicator duplication for library use
7.3 : Sub-communicators
7.3.1 : Scenario: distributed linear algebra
7.3.2 : Scenario: climate model
7.3.3 : Scenario: quicksort
7.3.4 : Shared memory
7.3.5 : Process spawning
7.4 : Splitting a communicator
7.5 : Communicators and groups
7.5.1 : Process groups
7.5.2 : Example
7.6 : Intercommunicators
7.6.1 : Intercommunicator point-to-point
7.6.2 : Intercommunicator collectives
7.6.3 : Intercommunicator querying
7.7 : Review questions
Back to Table of Contents
7 MPI topic: Communicators
A communicator is an object describing a group of processes. In many applications all processes work together closely coupled, and the only communicator you need is MPI_COMM_WORLD , the group describing all processes that your job starts with.
In this chapter you will see ways to make new groups of MPI processes: subgroups of the original world communicator. Chapter MPI topic: Process management discusses dynamic process management, which, while not extending MPI_COMM_WORLD does extend the set of available processes. That chapter also discusses the `sessions model', which is another way to constructing communicators.
7.1 Basic communicators
crumb trail: > mpi-comm > Basic communicators
There are three predefined communicators:
- MPI_COMM_WORLD comprises all processes that were started together by mpiexec (or some related program).
- MPI_COMM_SELF is the communicator that contains only the current process.
-
MPI_COMM_NULL
is the invalid communicator.
This values results
- when a communicator is freed; see section 7.3 ;
- as error return value from routines that construct communicators;
- for processes outside a created Cartesian communicator (section 11.1.1 );
- on non-spawned processes when querying their parent (section 7.6.3 ).
If you don't want to write MPI_COMM_WORLD repeatedly, you can assign that value to a variable of type MPI_Comm .
Examples:
// C: #include <mpi.h> MPI_Comm comm = MPI_COMM_WORLD;
!! Fortran 2008 interface use mpi_f08 Type(MPI_Comm) :: comm = MPI_COMM_WORLD
!! Fortran legacy interface #include <mpif.h> Integer :: comm = MPI_COMM_WORLD
Python note
comm = MPI.COMM_WORLD
MPL note The environment namespace has the equivalents of MPI_COMM_WORLD and MPI_COMM_SELF :
const communicator& mpl::environment::comm_world(); const communicator& mpl::environment::comm_self();There doesn't seem to be an equivalent of MPI_COMM_NULL . End of MPL note
MPL note Should you need the MPI_Comm object contained in an MPL communicator, there is an access function native_handle. \csnippetwithoutput{mplcommraw}{examples/mpi/mpl}{rawcompare} End of MPL note
You can name your communicators with MPI_Comm_set_name , which could improve the quality of error messages when they arise.
7.2 Duplicating communicators
crumb trail: > mpi-comm > Duplicating communicators
With MPI_Comm_dup you can make an exact duplicate of a communicator (see section 7.2.2 for an application). There is a nonblocking variant MPI_Comm_idup .
These calls do not propagate info hints (sections 15.1.1 and 15.1.1.2 ); to achieve this, use MPI_Comm_dup_with_info and MPI_Comm_idup_with_info ; section 15.1.1.2 .
Python note Duplicate communicators are created as output of the duplication routine:
newcomm = comm.Dup()
MPL note Communicators can be duplicated but only during initialization. Copy assignment has been deleted. Thus:
// LEGAL: mpl::communicator init = comm; // WRONG: mpl::communicator init; init = comm;End of MPL note
7.2.1 Communicator comparing
crumb trail: > mpi-comm > Duplicating communicators > Communicator comparing
You may wonder what `an exact copy' means precisely. For this, think of a communicator as a context label that you can attach to, among others, operations such as sends and receives. And it's that label that counts, not what processes are in the communicator. A send and a receive `belong together' if they have the same communicator context. Conversely, a send in one communicator can not be matched to a receive in a duplicate communicator, made by MPI_Comm_dup .
Testing whether two communicators are really the same is then more than testing if they comprise the same processes. The call MPI_Comm_compare returns MPI_IDENT if two communicator values are the same, and not if one is derived from the other by duplication: \csnippetwithoutput{commcopycompare}{examples/mpi/c}{commcompare}
Communicators that are not actually the same can be
- consisting of the same processes, in the same order, giving MPI_CONGRUENT ;
- merely consisting of the same processes, but not in the same order, giving MPI_SIMILAR ;
- different, giving MPI_UNEQUAL .
Comparing against MPI_COMM_NULL is not allowed.
7.2.2 Communicator duplication for library use
crumb trail: > mpi-comm > Duplicating communicators > Communicator duplication for library use
Duplicating a communicator may seem pointless, but it is actually very useful for the design of software libraries. Imagine that you have a code
MPI_Isend(...); MPI_Irecv(...); // library call MPI_Waitall(...);and suppose that the library has receive calls. Now it is possible that the receive in the library inadvertently catches the message that was sent in the outer environment.
Let us consider an example. First of all, here is code where the library stores the communicator of the calling program:
// commdupwrong.cxx
class library {
private:
MPI_Comm comm;
int procno,nprocs,other;
MPI_Request request[2];
public:
library(MPI_Comm incomm) {
comm = incomm;
MPI_Comm_rank(comm,&procno);
other = 1-procno;
};
int communication_start();
int communication_end();
};
This models a main program that does a simple message exchange, and it makes two calls to library routines. Unbeknown to the user, the library also issues send and receive calls, and they turn out to interfere.
Here
- The main program does a send,
- the library call function_start does a send and a receive; because the receive can match either send, it is paired with the first one;
- the main program does a receive, which will be paired with the send of the library call;
- both the main program and the library do a wait call, and in both cases all requests are succesfully fulfilled, just not the way you intended.
To prevent this confusion, the library should duplicate the outer communicator with MPI_Comm_dup and send all messages with respect to its duplicate. Now messages from the user code can never reach the library software, since they are on different communicators.
// commdupright.cxx
class library {
private:
MPI_Comm comm;
int procno,nprocs,other;
MPI_Request request[2];
public:
library(MPI_Comm incomm) {
MPI_Comm_dup(incomm,&comm);
MPI_Comm_rank(comm,&procno);
other = 1-procno;
};
library() {
MPI_Comm_free(&comm);
}
int communication_start();
int communication_end();
};
Note how the preceding example performs the MPI_Comm_free cal in a C++ destructor .
## commdup.py
class Library():
def __init__(self,comm):
# wrong: self.comm = comm
self.comm = comm.Dup()
self.other = self.comm.Get_size()-self.comm.Get_rank()-1
self.requests = [ None ] * 2
def __del__(self):
if self.comm.Get_rank()==0: print(".. freeing communicator")
self.comm.Free()
def communication_start(self):
sendbuf = np.empty(1,dtype=int); sendbuf[0] = 37
recvbuf = np.empty(1,dtype=int)
self.requests[0] = self.comm.Isend( sendbuf, dest=other,tag=2 )
self.requests[1] = self.comm.Irecv( recvbuf, source=other )
def communication_end(self):
MPI.Request.Waitall(self.requests)
mylibrary = Library(comm)
my_requests[0] = comm.Isend( sendbuffer,dest=other,tag=1 )
mylibrary.communication_start()
my_requests[1] = comm.Irecv( recvbuffer,source=other )
MPI.Request.Waitall(my_requests,my_status)
mylibrary.communication_end()
7.3 Sub-communicators
crumb trail: > mpi-comm > Sub-communicators
In many scenarios you divide a large job over all the available processors. However, your job may have two or more parts that can be considered as jobs by themselves. In that case it makes sense to divide your processors into subgroups accordingly.
Suppose for instance that you are running a simulation where inputs are generated, a computation is performed on them, and the results of this computation are analyzed or rendered graphically. You could then consider dividing your processors in three groups corresponding to generation, computation, rendering. As long as you only do sends and receives, this division works fine. However, if one group of processes needs to perform a collective operation, you don't want the other groups involved in this. Thus, you really want the three groups to be distinct from each other: you want them to be in separate communicators.
In order to make such subsets of processes, MPI has the mechanism of taking a subset of MPI_COMM_WORLD (or other communicator) and turning that subset into a new communicator.
Now you understand why the MPI collective calls had an argument for the communicator: a collective involves all processes of that communicator. By making a communicator that contains a subset of all available processes, you can do a collective on that subset.
The usage is as follows:
- You create a new communicator with routines such as MPI_Comm_dup (section 7.2 ), MPI_Comm_split (section 7.4 ), MPI_Comm_create (section 7.5 ), MPI_Intercomm_create (section 7.6 ), MPI_Comm_spawn (section 8.1 );
- you use that communiator for a while;
- and you call MPI_Comm_free when you are done with it; this also sets the communicator variable to MPI_COMM_NULL . A similar routine, MPI_Comm_disconnect waits for all pending communication to finish. Both are collective.
7.3.1 Scenario: distributed linear algebra
crumb trail: > mpi-comm > Sub-communicators > Scenario: distributed linear algebra
For scalability reasons (see Eijkhout:IntroHPC ), matrices should often be distributed in a 2D manner, that is, each process receives a subblock that is not a block of full columns or rows. This means that the processors themselves are, at least logically, organized in a 2D grid. Operations then involve reductions or broadcasts inside rows or columns. For this, a row or column of processors needs to be in a subcommunicator.
7.3.2 Scenario: climate model
crumb trail: > mpi-comm > Sub-communicators > Scenario: climate model
A climate simulation code has several components, for instance corresponding to land, air, ocean, and ice. You can imagine that each needs a different set of equations and algorithms to simulate. You can then divide your processes, where each subset simulates one component of the climate, occasionally communicating with the other components.
7.3.3 Scenario: quicksort
crumb trail: > mpi-comm > Sub-communicators > Scenario: quicksort
The popular quicksort algorithm works by splitting the data into two subsets that each can be sorted individually. If you want to sort in parallel, you could implement this by making two subcommunicators, and sorting the data on these, creating recursively more subcommunicators.
7.3.4 Shared memory
crumb trail: > mpi-comm > Sub-communicators > Shared memory
There is an important application of communicator splitting in the context of one-sided communication, grouping processes by whether they access the same shared memory area; see section 12.1 .
7.3.5 Process spawning
crumb trail: > mpi-comm > Sub-communicators > Process spawning
Finally, newly created communicators do not always need to be subset of the initial MPI_COMM_WORLD . MPI can dynamically spawn new processes (see chapter MPI topic: Process management ) which start in a MPI_COMM_WORLD of their own. However, another communicator will be created that spawns the old and new worlds so that you can communicate with the new processes.
7.4 Splitting a communicator
crumb trail: > mpi-comm > Splitting a communicator
Above we saw several scenarios where it makes sense to divide MPI_COMM_WORLD into disjoint subcommunicators. The command MPI_Comm_split uses a `color' to define these subcommunicators: all processes in the old communicator with the same color wind up in a new communicator together. The old communicator still exists, so processes now have two different contexts in which to communicate.
The ranking of processes in the new communicator is determined by a `key' value: in a subcommunicator the process with lowest key is given the lowest rank, et cetera. Most of the time, there is no reason to use a relative ranking that is different from the global ranking, so the MPI_Comm_rank value of the global communicator is a good choice. Any ties between identical key values are broken by using the rank from the original communicator. Thus, specifying zero are the key will also retain the original process ordering.
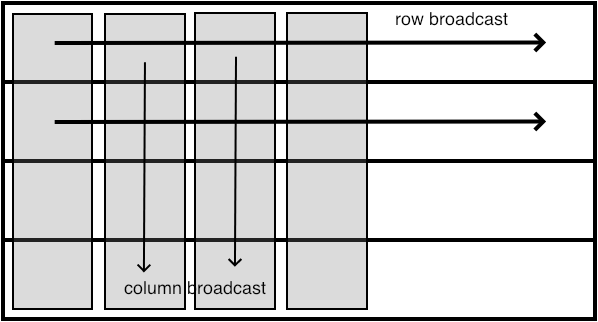
FIGURE 7.1: Row and column broadcasts in subcommunicators
Here is one example of communicator splitting. Suppose your processors are in a two-dimensional grid:
MPI_Comm_rank( MPI_COMM_WORLD, &mytid ); proc_i = mytid % proc_column_length; proc_j = mytid / proc_column_length;You can now create a communicator per column:
MPI_Comm column_comm; MPI_Comm_split( MPI_COMM_WORLD, proc_j, mytid, &column_comm );and do a broadcast in that column:
MPI_Bcast( data, /* stuff */, column_comm );Because of the SPMD nature of the program, you are now doing in parallel a broadcast in every processor column. Such operations often appear in dense linear algebra .
Exercise Organize your processes in a grid, and make subcommunicators for the rows and columns. For this compute the row and column number of each process.
In the row and column communicator, compute the rank. For instance, on a $2\times3$ processor grid you should find:
Global ranks: Ranks in row: Ranks in colum: 0 1 2 0 1 2 0 0 0 3 4 5 0 1 2 1 1 1
Check that the rank in the row communicator is the column number, and the other way around.
Run your code on different number of processes, for instance a number of rows and columns that is a power of 2, or that is a prime number.
(There is a skeleton code procgrid in the repository)
End of exercise
Python note In Python, the `key' argument is optional: \psnippetwithoutput{commsplitp}{examples/mpi/p}{dup}
MPL note In MPL , splitting a communicator is done as one of the overloads of the communicator constructor;
// commsplit.cxx // create sub communicator modulo 2 int color2 = procno % 2; mpl::communicator comm2( mpl::communicator::split, comm_world, color2 ); auto procno2 = comm2.rank();// create sub communicator modulo 4 recursively int color4 = procno2 % 2; mpl::communicator comm4( mpl::communicator::split, comm2, color4 ); auto procno4 = comm4.rank();
The communicator:: split identifier is an object of class communicator:: split_tag, itself is an otherwise empty subclass of communicator:
class split_tag {};
static constexpr split_tag split{};
End of MPL note
There is also a routine MPI_Comm_split_type which uses a type rather than a key to split the communicator. We will see this in action in section 12.1 .
As another example of communicator splitting, consider the recursive algorithm for matrix transposition .
Processors are organized in a square grid. The matrix is divided on $2\times 2$ block form.
Exercise Implement a recursive algorithm for matrix transposition:
![]()
- Swap blocks $(1,2)$ and $(2,1)$; then
- Divide the processors into four subcommunicators, and apply this algorithm recursively on each;
- If the communicator has only one process, transpose the matrix in place.
End of exercise
7.5 Communicators and groups
crumb trail: > mpi-comm > Communicators and groups
You saw in section 7.4 that it is possible derive communicators that have a subset of the processes of another communicator. There is a more general mechanism, using MPI_Group objects.
Using groups, it takes three steps to create a new communicator:
- Access the MPI_Group of a communicator object using MPI_Comm_group .
- Use various routines, discussed next, to form a new group.
- Make a new communicator object from the group with MPI_Group , using MPI_Comm_create
Creating a new communicator from a group is collective on the old communicator. There is also a routine MPI_Comm_create_group that only needs to be called on the group that constitutes the new communicator.
7.5.1 Process groups
crumb trail: > mpi-comm > Communicators and groups > Process groups
Groups are manipulated with MPI_Group_incl , MPI_Group_excl , MPI_Group_difference and a few more.
MPI_Comm_group (comm, group, ierr) MPI_Comm_create (MPI_Comm comm,MPI_Group group, MPI_Comm newcomm, ierr)
MPI_Group_union(group1, group2, newgroup, ierr) MPI_Group_intersection(group1, group2, newgroup, ierr) MPI_Group_difference(group1, group2, newgroup, ierr)
MPI_Group_size(group, size, ierr) MPI_Group_rank(group, rank, ierr)
Certain MPI types, MPI_Win and MPI_File , are created on a communicator. While you can not directly extract that communicator from the object, you can get the group with MPI_Win_get_group and MPI_File_get_group .
There is a pre-defined empty group MPI_GROUP_EMPTY , which can be used as an input to group construction routines, or appear as the result of such operations as a zero intersection. This not the same as MPI_GROUP_NULL , which is the output of invalid operations on groups, or the result of MPI_Group_free .
MPL note Should you need the MPI_Datatype object contained in an MPL group, there is an access function native_handle. End of MPL note
7.5.2 Example
crumb trail: > mpi-comm > Communicators and groups > Example
Suppose you want to split the world communicator into one manager process, with the remaining processes workers.
// portapp.c
MPI_Comm comm_work;
{
MPI_Group world_group,work_group;
MPI_Comm_group( comm_world,&world_group );
int manager[] = {0};
MPI_Group_excl( world_group,1,manager,&work_group );
MPI_Comm_create( comm_world,work_group,&comm_work );
MPI_Group_free( &world_group ); MPI_Group_free( &work_group );
}
7.6 Intercommunicators
crumb trail: > mpi-comm > Intercommunicators
In several scenarios it may be desirable to have a way to communicate between communicators. For instance, an application can have clearly functionally separated modules (preprocessor, simulation, postprocessor) that need to stream data pairwise. In another example, dynamically spawned processes (section 8.1 ) get their own value of MPI_COMM_WORLD , but still need to communicate with the process(es) that spawned them. In this section we will discuss the inter-communicators mechanism that serves such use cases.
Communicating between disjoint communicators can of course be done by having a communicator that overlaps them, but this would be complicated: since the `inter' communication happens in the overlap communicator, you have to translate its ordering into those of the two worker communicators. It would be easier to express messages directly in terms of those communicators, and this is what happens in an inter-communicators .
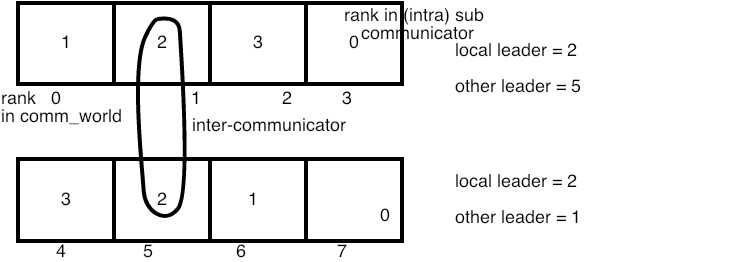
FIGURE 7.2: Illustration of ranks in an intercommunicator setup
A call to MPI_Intercomm_create involves the following communicators:
- Two local communicators, which in this context are known as intra-communicators s: one process in each will act as the local leader, connected to the remote leader;
- The peer communicator , often MPI_COMM_WORLD , that contains the local communicators;
- An \indextermsubdefh{inter}{communicator} that allows the leaders of the subcommunicators to communicate with the other subcommunicator.
7.6.1 Intercommunicator point-to-point
crumb trail: > mpi-comm > Intercommunicators > Intercommunicator point-to-point
The local leaders can now communicate with each other.
- The sender specifies as target the local number of the other leader in the other sub-communicator;
- Likewise, the receiver specifies as source the local number of the sender in its sub-communicator.
if (i_am_local_leader) {
if (color==0) {
interdata = 1.2;
int inter_target = local_number_of_other_leader;
printf("[%d] sending interdata %e to %d\n",
procno,interdata,inter_target);
MPI_Send(&interdata,1,MPI_DOUBLE,inter_target,0,intercomm);
} else {
MPI_Status status;
MPI_Recv(&interdata,1,MPI_DOUBLE,MPI_ANY_SOURCE,MPI_ANY_TAG,intercomm,&status);
int inter_source = status.MPI_SOURCE;
printf("[%d] received interdata %e from %d\n",
procno,interdata,inter_source);
if (inter_source!=local_number_of_other_leader)
fprintf(stderr,
"Got inter communication from unexpected %d; s/b %d\n",
inter_source,local_number_of_other_leader);
}
}
7.6.2 Intercommunicator collectives
crumb trail: > mpi-comm > Intercommunicators > Intercommunicator collectives
The intercommunicator can be used in collectives such as a broadcast.
- In the sending group, the root process passes MPI_ROOT as `root' value; all others use MPI_PROC_NULL .
- In the receiving group, all processes use a `root' value that is the rank of the root process in the root group. Note: this is not the global rank!
Intercommunicators can be used if two groups of process work asynchronously with respect to each other; another application is fault tolerance (section 15.5 ).
if (color==0) { // sending group: the local leader sends
if (i_am_local_leader)
root = MPI_ROOT;
else
root = MPI_PROC_NULL;
} else { // receiving group: everyone indicates leader of other group
root = local_number_of_other_leader;
}
if (DEBUG) fprintf(stderr,"[%d] using root value %d\n",procno,root);
MPI_Bcast(&bcast_data,1,MPI_INT,root,intercomm);
7.6.3 Intercommunicator querying
crumb trail: > mpi-comm > Intercommunicators > Intercommunicator querying
Some of the operations you have seen before for intra-communicators s behave differently with intercommunicator:
- MPI_Comm_size returns the size of the local group, not the size of the intercommunicator.
- MPI_Comm_rank returns the rank in the local group.
- MPI_Comm_group returns the local group.
Spawned processes can find their parent communicator with MPI_Comm_get_parent (see examples in section 8.1 ). On other processes this returns MPI_COMM_NULL .
Test whether a communicator is intra or inter: MPI_Comm_test_inter .
MPI_Comm_compare works for intercommunicators.
Processes connected through an intercommunicator can query the size of the `other' communicator with MPI_Comm_remote_size . The actual group can be obtained with MPI_Comm_remote_group .
Virtual topologies (chapter MPI topic: Topologies ) cannot be created with an intercommunicator. To set up virtual topologies, first transform the intercommunicator to an intracommunicator with the function MPI_Intercomm_merge .
\newpage
7.7 Review questions
crumb trail: > mpi-comm > Review questionsFor all true/false questions, if you answer that a statement is false, give a one-line explanation.
-
True or false: in each communicator, processes are numbered consecutively from zero.
-
If a process is in two communicators, it has the same rank in
both.
-
Any communicator that is not
MPI_COMM_WORLD
is a strict subset of it.
-
The subcommunicators derived by
MPI_Comm_split
are disjoint.
-
If two processes have ranks $p