MPI leftover topics
Experimental html version of Parallel Programming in MPI, OpenMP, and PETSc by Victor Eijkhout. download the textbook at https:/theartofhpc.com/pcse
15.1.1 : Info objects
15.1.1.1 : Environment information
15.1.1.2 : Communicator and window information
15.1.1.3 : File information
15.1.2 : Attributes
15.1.3 : Create new keyval attributes
15.1.4 : Processor name
15.1.5 : Version information
15.1.6 : Python utility functions
15.2 : Error handling
15.2.1 : Error codes
15.2.2 : Error handling
15.2.2.1 : Abort
15.2.2.2 : Return
15.2.2.3 : Error printing
15.2.3 : Defining your own MPI errors
15.3 : Fortran issues
15.3.1 : Assumed-shape arrays
15.3.2 : Prevent compiler optimizations
15.4 : Progress
15.5 : Fault tolerance
15.6 : Performance, tools, and profiling
15.6.1 : Timing
15.6.1.1 : Global timing
15.6.1.2 : Local timing
15.6.2 : Simple profiling
15.6.3 : Programming for performance
15.6.4 : MPIR
15.7 : Determinism
15.8 : Subtleties with processor synchronization
15.9 : Shell interaction
15.9.1 : Standard input
15.9.2 : Standard out and error
15.9.3 : Process status
15.9.4 : Multiple program start
15.10 : Leftover topics
15.10.1 : MPI constants
15.10.2 : Cancelling messages
15.10.3 : The origin of one-sided communication in ShMem
15.11 : Literature
Back to Table of Contents
15 MPI leftover topics
15.1 Contextual information, attributes, etc.
crumb trail: > mpi > Contextual information, attributes, etc.
15.1.1 Info objects
crumb trail: > mpi > Contextual information, attributes, etc. > Info objects
Certain MPI routines can accept MPI_Info objects. (For files, see section 15.1.1.3 , for windows, see section 9.5.4 .) These contain key-value pairs that can offer system or implementation dependent information.
Create an info object with MPI_Info_create and delete it with MPI_Info_free .
Keys are then set with MPI_Info_set , and they can be queried with MPI_Info_get . Note that the output of the `get' routine is not allocated: it is a buffer that is passed. The maximum length of a key is given by the parameter MPI_MAX_INFO_KEY . You can delete a key from an info object with MPI_Info_delete .
There is a straightforward duplication of info objects: MPI_Info_dup .
You can also query the number of keys in an info object with MPI_Info_get_nkeys , after which the keys can be queried in succession with MPI_Info_get_nthkey
Info objects that are marked as `In' or `Inout' arguments are parsed before that routine returns. This means that in nonblocking routines they can be freed immediately, unlike, for instance, send buffers.
\begin{mpifournote} {Info with null terminator} The routines \indexmpidepr{MPI_Info_get} and \indexmpidepr{MPI_Info_get_valuelen} are not robust with respect to the C language null terminator . Therefore, they are deprecated, and should be replaced with MPI_Info_get_string , which always returns a null-terminated string.
int MPI_Info_get_string
(MPI_Info info, const char *key,
int *buflen, char *value, int *flag)
\end{mpifournote}
15.1.1.1 Environment information
crumb trail: > mpi > Contextual information, attributes, etc. > Info objects > Environment information
The object MPI_INFO_ENV is predefined, containing:
- command Name of program executed.
- argv Space separated arguments to command.
- maxprocs Maximum number of MPI processes to start.
- soft Allowed values for number of processors.
- host Hostname.
- arch Architecture name.
- wdir Working directory of the MPI process.
- file Value is the name of a file in which additional information is specified.
- thread_level Requested level of thread support, if requested before the program started execution.
15.1.1.2 Communicator and window information
crumb trail: > mpi > Contextual information, attributes, etc. > Info objects > Communicator and window information
MPI has a built-in possibility of attaching information to communicators and windows using the calls MPI_Comm_get_info MPI_Comm_set_info , MPI_Win_get_info , MPI_Win_set_info .
Copying a communicator with MPI_Comm_dup does not cause the info to be copied; to propagate information to the copy there is MPI_Comm_dup_with_info (section 7.2 ).
15.1.1.3 File information
crumb trail: > mpi > Contextual information, attributes, etc. > Info objects > File information
An MPI_Info object can be passed to the following file routines:
- MPI_File_open
- MPI_File_set_view
- MPI_File_set_info ; collective. The converse routine is MPI_File_get_info .
The following keys are defined in the MPI-2 standard:
- access_style : A comma separated list of one or more of: read_once , write_once , read_mostly , write_mostly , sequential , reverse_sequential , random
- collective_buffering : true or false; enables or disables buffering on collective I/O operations
- cb_block_size : integer block size for collective buffering, in bytes
- cb_buffer_size : integer buffer size for collective buffering, in bytes
- cb_nodes : integer number of MPI processes used in collective buffering
- chunked : a comma separated list of integers describing the dimensions of a multidimensional array to be accessed using subarrays, starting with the most significant dimension (1st in C, last in Fortran)
- chunked_item : a comma separated list specifying the size of each array entry, in bytes
- chunked_size : a comma separated list specifying the size of the subarrays used in chunking
- file_perm : UNIX file permissions at time of creation, in octal
- io_node_list : a comma separated list of I/O nodes to use \begin{mpifournote} {Memory alignment}
- mpi_minimum_memory_alignment : aligment of allocated memory. \end{mpifournote}
- nb_proc : integer number of processes expected to access a file simultaneously
- num_io_nodes : integer number of I/O nodes to use
- striping_factor : integer number of I/O nodes/devices a file should be striped across
- striping_unit : integer stripe size, in bytes
15.1.2 Attributes
crumb trail: > mpi > Contextual information, attributes, etc. > Attributes
Some runtime (or installation dependendent) values are available as attributes through MPI_Comm_set_attr and MPI_Comm_get_attr for communicators, or MPI_Win_get_attr , MPI_Type_get_attr . (The MPI-2 routine MPI_Attr_get is deprecated). The flag parameter has two functions:
- it returns whether the attributed was found;
- if on entry it was set to false, the value parameter is ignored and the routines only tests whether the key is present.
// tags.c int tag_upperbound; void *v; int flag=1; ierr = MPI_Comm_get_attr(comm,MPI_TAG_UB,&v,&flag); tag_upperbound = *(int*)v;
## tags.py
tag_upperbound = comm.Get_attr(MPI.TAG_UB)
if procid==0:
print("Determined tag upperbound: {}".format(tag_upperbound))
Attributes are:
- MPI_TAG_UB Upper bound for tag value . (The lower bound is zero.) Note that MPI_TAG_UB is the key, not the actual upper bound! This value has to be at least 32767.
- \indexmpidepr{MPI_HOST} Host process rank, if such exists, MPI_PROC_NULL , otherwise. The standard does not define what it means to be a host, or even whether there should be one to begin with.
- MPI_IO rank of a node that has regular I/O facilities. Nodes in the same communicator may return different values for this parameter. If this return MPI_ANY_SOURCE , all ranks can perform I/O.
- MPI_WTIME_IS_GLOBAL Boolean variable that indicates whether clocks are synchronized.
Also:
-
MPI_UNIVERSE_SIZE
: the total number of processes
that can be created. This can be more than the size of
MPI_COMM_WORLD
if the host list is larger than the number of
initially started processes. See section
8.1
.
- MPI_APPNUM : if MPI is used in MPMD mode (section 15.9.4 ), or if MPI_Comm_spawn_multiple is used (section 8.1 ), this attribute reports the how-manieth program we are in.
Fortran note Fortran has none of this double indirection stuff. The value of the attribute is returned immediately, as an integer of kind MPI_ADDRESS_KIND :
!! tags.F90
logical :: flag
integer(KIND=MPI_ADDRESS_KIND) :: attr_v,tag_upperbound
call MPI_Comm_get_attr(comm,MPI_TAG_UB,attr_v,flag,ierr)
tag_upperbound = attr_v
print '("Determined tag upperbound: ",i9)', tag_upperbound
Python note mpi4py.MPI.UNIVERSE_SIZE .
15.1.3 Create new keyval attributes
crumb trail: > mpi > Contextual information, attributes, etc. > Create new keyval attributes
Create a key value with MPI_Comm_create_keyval , MPI_Type_create_keyval , MPI_Win_create_keyval . Use this key to set new attributes with MPI_Comm_set_attr , MPI_Type_set_attr , MPI_Win_set_attr . Free the attributed with MPI_Comm_delete_attr , MPI_Type_delete_attr , MPI_Win_delete_attr .
This uses a function type MPI_Comm_attr_function . This function is copied when a communicator is duplicated; section 7.2 . Free with MPI_Comm_free_keyval .
15.1.4 Processor name
crumb trail: > mpi > Contextual information, attributes, etc. > Processor name
You can query the hostname of a processor with MPI_Get_processor_name . This name need not be unique between different processor ranks.
You have to pass in the character storage: the character array must be at least MPI_MAX_PROCESSOR_NAME characters long. The actual length of the name is returned in the resultlen parameter.
15.1.5 Version information
crumb trail: > mpi > Contextual information, attributes, etc. > Version information
For runtime determination, The MPI version is available through two parameters MPI_VERSION and MPI_SUBVERSION or the function MPI_Get_version .
The library version can be queried with MPI_Get_library_version . The result string has to fit in MPI_MAX_LIBRARY_VERSION_STRING .
Python note A function is available for version and subversion, as well as explicit parameters: \psnippetwithoutput{mpiversionp}{examples/mpi/p}{version}
15.1.6 Python utility functions
crumb trail: > mpi > Contextual information, attributes, etc. > Python utility functions
Python note \small
## util.py
print(f"Configuration:\n{mpi4py.get_config()}")
print(f"Include dir:\n{mpi4py.get_include()}")
Configuration:
{'mpicc': '/opt/local/bin/mpicc-mpich-mp'}
Include dir:
/opt/local/Library/Frameworks/Python.framework/Versions/3.8/lib/python3.8/site-packages/mpi4py/include
Intel compiler and locally installed Python:
Configuration:
{'mpicc': '/opt/intel/compilers_and_libraries_2020.4.304/linux/mpi/intel64/bin/mpicc',
'mpicxx': '/opt/intel/compilers_and_libraries_2020.4.304/linux/mpi/intel64/bin/mpicxx',
'mpifort': '/opt/intel/compilers_and_libraries_2020.4.304/linux/mpi/intel64/bin/mpif90',
'mpif90': '/opt/intel/compilers_and_libraries_2020.4.304/linux/mpi/intel64/bin/mpif90',
'mpif77': '/opt/intel/compilers_and_libraries_2020.4.304/linux/mpi/intel64/bin/mpif77'}
Include dir:
/opt/apps/intel19/impi19_0/python3/3.9.2/lib/python3.9/site-packages/mpi4py/include
15.2 Error handling
crumb trail: > mpi > Error handling
Errors in normal programs can be tricky to deal with; errors in parallel programs can be even harder. This is because in addition to everything that can go wrong with a single executable (floating point errors, memory violation) you now get errors that come from faulty interaction between multiple executables.
A few examples of what can go wrong:
- MPI errors: an MPI routine can exit prematurely for various reasons, such as receiving much more data than its buffer can accomodate. Such errors, as well as the more common type mentioned above, typically cause your whole execution to terminate. That is, if one incarnation of your executable exits, the MPI runtime will kill all others.
- Deadlocks and other hanging executions: there are various scenarios where your processes individually do not exit, but are all waiting for each other. This can happen if two processes are both waiting for a message from each other, and this can be helped by using nonblocking calls. In another scenario, through an error in program logic, one process will be waiting for more messages (including nonblocking ones) than are sent to it.
While it is desirable for an MPI implementation to return an error, this is not always possible. Therefore, some scenarios, whether supplying certain procedure arguments, or doing a certain sequence of procedure calls, are simply marked as `erroneous', and the state of MPI after an erroneous call is undefined.
15.2.1 Error codes
crumb trail: > mpi > Error handling > Error codes
There are a bunch of error codes. These are all positive int values, while MPI_SUCCESS is zero. The maximum value of any built-in error code is MPI_ERR_LASTCODE . User-defined error codes are all larger than this.
- MPI_ERR_ARG : an argument was invalid that is not covered by another error code.
- MPI_ERR_BUFFER The buffer pointer is invalid; this typically means that you have supplied a null pointer.
- MPI_ERR_COMM : invalid communicator. A common error is to use a null communicator in a call.
- MPI_ERR_COUNT Invalid count argument, usually this is caused by a negative count value; zero is often a valid count.
- MPI_ERR_INTERN An internal error in MPI has been detected.
- MPI_ERR_IN_STATUS A functioning returning an array of statuses has at least one status where the MPI_ERROR field is set to other than MPI_SUCCESS . See section 4.3.3 .
- MPI_ERR_INFO : invalid info object.
- MPI_ERR_NO_MEM is returned by MPI_Alloc_mem if memory is exhausted.
- MPI_ERR_OTHER : an error occurred; use MPI_Error_string to retrieve further information about this error; see section 15.2.2.3 .
- MPI_ERR_PORT : invalid port; this applies to MPI_Comm_connect and such. \begin{mpifournote} {Error code for aborted process}
- MPI_ERR_PROC_ABORTED is returned if a process tries to communicate with a process that has aborted. \end{mpifournote}
- MPI_ERR_RANK : an invalid source or destination rank is specified. Valid ranks are $0\ldots s-1$ where $s$ is the size of the communicator, or MPI_PROC_NULL , or MPI_ANY_SOURCE for receive operations.
- MPI_ERR_SERVICE : invalid service in MPI_Unpublish_name ; section 8.2.3 .
15.2.2 Error handling
crumb trail: > mpi > Error handling > Error handling
The MPI library has a general mechanism for dealing with errors that it detects: one can specify an error handler, specific to MPI objects.
- Most commonly, an error handler is associated with a communicator: MPI_Comm_set_errhandler (and likewise it can be retrieved with MPI_Comm_get_errhandler );
- other possibilities are MPI_File_set_errhandler , MPI_File_call_errhandler , \begin{mpifournote} {Error handler for session} MPI_Session_set_errhandler , MPI_Session_call_errhandler , \end{mpifournote} MPI_Win_set_errhandler , MPI_Win_call_errhandler .
Remark
The routine
MPI_Errhandler_set
is deprecated,
replaced by its MPI-2 variant
MPI_Comm_set_errhandler
.
End of remark
Some handlers of type MPI_Errhandler are predefined ( MPI_ERRORS_ARE_FATAL , MPI_ERRORS_ABORT , MPI_ERRORS_RETURN ; see below), but you can define your own with MPI_Errhandler_create , to be freed later with MPI_Errhandler_free .
By default, MPI uses MPI_ERRORS_ARE_FATAL , except for file operations; see section 10.5 .
Python note The policy for dealing with errors can be set through the mpi4py.rc object (section 2.2.2 ):
mpi4py.rc.errors # default: "exception"Available levels are exception , default , fatal .
15.2.2.1 Abort
crumb trail: > mpi > Error handling > Error handling > Abort
The default behavior, where the full run is aborted, is equivalent to your code having the following call to
MPI_Comm_set_errhandler(MPI_COMM_WORLD,MPI_ERRORS_ARE_FATAL);
The handler MPI_ERRORS_ARE_FATAL , even though it is associated with a communicator, causes the whole application to abort.
\begin{mpifournote} {Abort on communicator} The handler MPI_ERRORS_ABORT (MPI-4) aborts on the processes in the communicator for which it is specified. \end{mpifournote}
15.2.2.2 Return
crumb trail: > mpi > Error handling > Error handling > Return
Another simple possibility is to specify MPI_ERRORS_RETURN :
MPI_Comm_set_errhandler(MPI_COMM_WORLD,MPI_ERRORS_RETURN);which causes the error code to be returned to the user. This gives you the opportunity to write code that handles the error return value; see the next section.
15.2.2.3 Error printing
crumb trail: > mpi > Error handling > Error handling > Error printing
If the MPI_Errhandler value MPI_ERRORS_RETURN is used, you can compare the return code to MPI_SUCCESS and print out debugging information:
int ierr;
ierr = MPI_Something();
if (ierr!=MPI_SUCCESS) {
// print out information about what your programming is doing
MPI_Abort();
}
For instance,
Fatal error in MPI_Waitall: See the MPI_ERROR field in MPI_Status for the error codeYou could then retrieve the MPI_ERROR field of the status, and print out an error string with MPI_Error_string or maximal size MPI_MAX_ERROR_STRING :
MPI_Comm_set_errhandler(MPI_COMM_WORLD,MPI_ERRORS_RETURN);
ierr = MPI_Waitall(2*ntids-2,requests,status);
if (ierr!=0) {
char errtxt[MPI_MAX_ERROR_STRING];
for (int i=0; i<2*ntids-2; i++) {
int err = status[i].MPI_ERROR;
int len=MPI_MAX_ERROR_STRING;
MPI_Error_string(err,errtxt,&len);
printf("Waitall error: %d %s\n",err,errtxt);
}
MPI_Abort(MPI_COMM_WORLD,0);
}
I/O}: if an output file has the wrong
permissions, code can possibly progress without writing data, or
writing to a temporary file.
MPI operators ( MPI_Op ) do not return an error code. In case of an error they call MPI_Abort ; if MPI_ERRORS_RETURN is the error handler, error codes may be silently ignored.
You can create your own error handler with MPI_Comm_create_errhandler , which is then installed with MPI_Comm_set_errhandler . You can retrieve the error handler with MPI_Comm_get_errhandler .
MPL note MPL does not allow for access to the wrapped communicators. However, for MPI_COMM_WORLD , the routine MPI_Comm_set_errhandler can be called directly. End of MPL note
15.2.3 Defining your own MPI errors
crumb trail: > mpi > Error handling > Defining your own MPI errors
You can define your own errors that behave like MPI errors. As an example, let's write a send routine that refuses to send zero-sized data.
The first step to defining a new error is to define an error class with MPI_Add_error_class :
int nonzero_class; MPI_Add_error_class(&nonzero_class);This error number is larger than MPI_ERR_LASTCODE , the upper bound on built-in error codes. The attribute MPI_LASTUSEDCODE records the last issued value.
Your new error code is then defined in this class with MPI_Add_error_code , and an error string can be added with MPI_Add_error_string :
int nonzero_code; MPI_Add_error_code(nonzero_class,&nonzero_code); MPI_Add_error_string(nonzero_code,"Attempting to send zero buffer");
You can then call an error handler with this code. For instance to have a wrapped send routine that will not send zero-sized messages:
// errorclass.c
int MyPI_Send( void *buffer,int n,MPI_Datatype type, int target,int tag,MPI_Comm comm) {
if (n==0)
MPI_Comm_call_errhandler( comm,nonzero_code );
MPI_Ssend(buffer,n,type,target,tag,comm);
return MPI_SUCCESS;
};
We test our example:
for (int msgsize=1; msgsize>=0; msgsize--) {
double buffer;
if (procno==0) {
printf("Trying to send buffer of length %d\n",msgsize);
MyPI_Send(&buffer,msgsize,MPI_DOUBLE, 1,0,comm);
printf(".. success\n");
} else if (procno==1) {
MPI_Recv (&buffer,msgsize,MPI_DOUBLE, 0,0,comm,MPI_STATUS_IGNORE);
}
}
Trying to send buffer of length 1 .. success Trying to send buffer of length 0 Abort(1073742081) on node 0 (rank 0 in comm 0): Fatal error in MPI_Comm_call_errhandler: Attempting to send zero buffer
15.3 Fortran issues
crumb trail: > mpi > Fortran issues
MPI is typically written in C, what if you program Fortran ?
See section 6.2.2.1 for MPI types corresponding to Fortran90 types
15.3.1 Assumed-shape arrays
crumb trail: > mpi > Fortran issues > Assumed-shape arrays
Use of other than contiguous data, for instance A(1:N:2) , was a problem in MPI calls, especially nonblocking ones. In that case it was best to copy the data to a contiguous array. This has been fixed in MPI-3.
- Fortran routines have the same signature as C routines except for the addition of an integer error parameter.
- The call for MPI_Init in Fortran \indexmpishowf{MPI_Init} in Fortran does not have the commandline arguments; they need to be handled separately.
- The routine MPI_Sizeof is only available in Fortran, it provides the functionality of the C/C++ operator sizeof .
15.3.2 Prevent compiler optimizations
crumb trail: > mpi > Fortran issues > Prevent compiler optimizations
The Fortran compiler can aggressively optimize by rearranging instructions. This may lead to incorrect behavior in MPI code. In the sequence:
call MPI_Isend( buf, ..., request ) call MPI_Wait(request) print *,buf(1)the wait call does not involve the buffer, so the compiler can translate this into
call MPI_Isend( buf, ..., request ) register = buf(1) call MPI_Wait(request) print *,registerPreventing this is possible with a Fortran2018 mechanism. First of all the buffer should be declared asynchronous
<type>,Asynchronous :: bufand introducing
IF (.NOT. MPI_ASYNC_PROTECTS_NONBLOCKING) &
CALL MPI_F_SYNC_REG( buf )
The call to
MPI_F_sync_reg
will be removed at compile time if
MPI_ASYNC_PROTECTS_NONBLOCKING
is true.
15.4 Progress
The concept asynchronous progress describes that MPI messages continue on their way through the network, while the application is otherwise busy.
The problem here is that, unlike straight MPI_Send and MPI_Recv calls, communication of this sort can typically not be off-loaded to the network card, so different mechanisms are needed.
This can happen in a number of ways:
- Compute nodes may have a dedicated communications processor. The Intel Paragon was of this design; modern multicore processors are a more efficient realization of this idea.
- The MPI library may reserve a core or thread for communications processing. This is implementation dependent; see Intel MPI information below.
- Reserving a core, or a thread in a continuous busy-wait spin loop , takes away possible performance from the code. For this reason, Ruhela et al. [ruhela-eurompi18] propose using a pthreads signal to wake up the progress thread.
- Absent such dedicated resources, the application can force MPI to make progress by occasional calls to a polling routine such as MPI_Iprobe .
Remark The MPI_Probe call is somewhat similar, in spirit if not quite in functionality, as MPI_Test . However, they behave differently with respect to progress. Quoting the standard:
The MPI implementation of MPI_Probe and MPI_Iprobe needs to guarantee progress: if a call to MPI_Probe has been issued by a process, and a send that matches the probe has been initiated by some process, then the call to MPI_Probe will return.
In other words: probing causes MPI to make progress. On the other hand,
A call to MPI_Test returns flag = true if the operation identified by request is complete.
In other words, if progress has been made, then testing will report completion,
but by itself it does not cause completion.
End of remark
A similar problem arises with passive target synchronization: it is possible that the origin process may hang until the target process makes an MPI call.
The following commands force progress: MPI_Win_test , MPI_Request_get_status .
Intel note Only available with the release_mt and debug_mt versions of the Intel MPI library. Set I_MPI_ASYNC_PROGRESS to 1 to enable asynchronous progress threads, and I_MPI_ASYNC_PROGRESS_THREADS to set the number of progress threads.
See https://software.intel.com/en-us/mpi-developer-guide-linux-asynchronous-progress-control ,
End of Intel note
Progress issues play with: MPI_Test , MPI_Request_get_status , MPI_Win_test .
15.5 Fault tolerance
crumb trail: > mpi > Fault tolerance
Processors are not completely reliable, so it may happen that one `breaks': for software or hardware reasons it becomes unresponsive. For an MPI program this means that it becomes impossible to send data to it, and any collective operation involving it will hang. Can we deal with this case? Yes, but it involves some programming.
First of all, one of the possible MPI error return codes (section 15.2 ) is MPI_ERR_COMM , which can be returned if a processor in the communicator is unavailable. You may want to catch this error, and add a `replacement processor' to the program. For this, the MPI_Comm_spawn can be used (see 8.1 for details). But this requires a change of program design: the communicator containing the new process(es) is not part of the old MPI_COMM_WORLD , so it is better to set up your code as a collection of inter-communicators to begin with.
15.6 Performance, tools, and profiling
crumb trail: > mpi > Performance, tools, and profiling
In most of this book we talk about functionality of the MPI library. There are cases where a problem can be solved in more than one way, and then we wonder which one is the most efficient. In this section we will explicitly address performance. We start with two sections on the mere act of measuring performance.
15.6.1 Timing
crumb trail: > mpi > Performance, tools, and profiling > Timing
MPI has a wall clock timer: MPI_Wtime which gives the number of seconds from a certain point in the past. (Note the absence of the error parameter in the fortran call.)
double t;
t = MPI_Wtime();
for (int n=0; n<NEXPERIMENTS; n++) {
// do something;
}
t = MPI_Wtime()-t; t /= NEXPERIMENTS;
The timer has a resolution of MPI_Wtick .
MPL note The timing routines wtime and wtick and wtime_is_global are environment methods:
double mpl::environment::wtime (); double mpl::environment::wtick (); bool mpl::environment::wtime_is_global ();End of MPL note
Timing in parallel is a tricky issue. For instance, most clusters do not have a central clock, so you can not relate start and stop times on one process to those on another. You can test for a global clock as follows MPI_WTIME_IS_GLOBAL :
int *v,flag;
MPI_Attr_get( comm, MPI_WTIME_IS_GLOBAL, &v, &flag );
if (mytid==0) printf("Time synchronized? %d->%d\n",flag,*v);
Normally you don't worry about the starting point for this timer: you call it before and after an event and subtract the values.
t = MPI_Wtime(); // something happens here t = MPI_Wtime()-t;If you execute this on a single processor you get fairly reliable timings, except that you would need to subtract the overhead for the timer. This is the usual way to measure timer overhead:
t = MPI_Wtime(); // absolutely nothing here t = MPI_Wtime()-t;
15.6.1.1 Global timing
crumb trail: > mpi > Performance, tools, and profiling > Timing > Global timing
However, if you try to time a parallel application you will most likely get different times for each process, so you would have to take the average or maximum. Another solution is to synchronize the processors by using a barrier through MPI_Barrier :
MPI_Barrier(comm) t = MPI_Wtime(); // something happens here MPI_Barrier(comm) t = MPI_Wtime()-t;
Exercise
This scheme also has some overhead associated with it. How would you measure that?
End of exercise
15.6.1.2 Local timing
crumb trail: > mpi > Performance, tools, and profiling > Timing > Local timing
Now suppose you want to measure the time for a single send. It is not possible to start a clock on the sender and do the second measurement on the receiver, because the two clocks need not be synchronized. Usually a ping-pong is done:
if ( proc_source ) {
MPI_Send( /* to target */ );
MPI_Recv( /* from target */ );
else if ( proc_target ) {
MPI_Recv( /* from source */ );
MPI_Send( /* to source */ );
}
No matter what sort of timing you are doing, it is good to know the accuracy of your timer. The routine MPI_Wtick gives the smallest possible timer increment. If you find that your timing result is too close to this `tick', you need to find a better timer (for CPU measurements there are cycle-accurate timers), or you need to increase your running time, for instance by increasing the amount of data.
15.6.2 Simple profiling
crumb trail: > mpi > Performance, tools, and profiling > Simple profiling
Remark
This section describes MPI profiling before the introduction of the
MPI tools interface
. For that, see chapter
MPI topic: Tools interface
.
End of remark
MPI allows you to write your own profiling interface. To make this possible, every routine MPI_Something calls a routine PMPI_Something that does the actual work. You can now write your MPI_... routine which calls PMPI_... , and inserting your own profiling calls.

FIGURE 15.1: Calling hierarchy of MPI and PMPI routines
See figure 15.1 .
By default, the MPI routines are defined as weak linker symbols as a synonym of the PMPI ones. In the gcc case:
#pragma weak MPI_Send = PMPI_Send
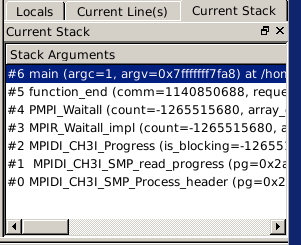
FIGURE 15.2: A stack trace, showing the \texttt{PMPI} calls.
As you can see in figure 15.2 , normally only the PMPI routines show up in the stack trace.
15.6.3 Programming for performance
crumb trail: > mpi > Performance, tools, and profiling > Programming for performance
We outline some issues pertaining to performance.
Eager limit
Short blocking messages are handled by a simpler mechanism than longer. The limit on what is considered `short' is known as the eager limit (section 4.1.4.2 ), and you could tune your code by increasing its value. However, note that a process may likely have a buffer accomodating eager sends for every single other process. This may eat into your available memory.
Blocking versus nonblocking
The issue of
blocking versus nonblocking
communication is something of a red herring. While nonblocking
communication allows
latency hiding
, we can not
consider it an alternative to blocking sends, since replacing
nonblocking by blocking calls will usually give
deadlock
.
Still, even if you use nonblocking communication for the mere avoidance of deadlock or serialization (section 4.1.4.3 ), bear in mind the possibility of overlap of communication and computation. This also brings us to our next point.
Looking at it the other way around, in a code with blocking sends you may get better performance from nonblocking, even if that is not structurally necessary.
Progress
MPI is not magically active in the background, especially if the user code is doing scalar work that does not involve MPI. As sketched in section 15.4 , there are various ways of ensuring that latency hiding actually happens.
Persistent sends
If a communication between the same pair of processes, involving the same buffer, happens regularly, it is possible to set up a persistent communication . See section 5.1 .
Buffering
MPI uses internal buffers, and the copying from user data to these buffers may affect performance. For instance, derived types (section 6.3 ) can typically not be streamed straight through the network (this requires special hardware support [LI:MpiDataUMR] ) so they are first copied. Somewhat surprisingly, we find that buffered communication (section 5.5 ) does not help. Perhaps MPI implementors have not optimized this mode since it is so rarely used.
This is issue is extensively investigated in [Eijkhout:MPItype-arxiv] .
Graph topology and neighborhood collectives
Load balancing and communication minimization are important in irregular applications. There are dedicated programs for this ( ParMetis , Zoltan ), and libraries such as PETSc may offer convenient access to such capabilities.
In the declaration of a graph topology (section 11.2 ) MPI is allowed to reorder processes, which could be used to support such activities. It can also serve for better message sequencing when neighborhood collectives are used.
Network issues
In the discussion so far we have assumed that the network is a perfect conduit for data. However, there are issues of port design, in particular caused by oversubscription adversely affect performance. While in an ideal world it may be possible to set up routine to avoid this, in the actual practice of a supercomputer cluster, network contention or message collision from different user jobs is hard to avoid.
Offloading and onloading
There are different philosophies of network card design Mellanox , being a network card manufacturer, believes in off-loading network activity to the NIC , while Intel , being a processor manufacturer, believes in `on-loading' activity to the process. There are argument either way.
Either way, investigate the capabilities of your network.
15.6.4 MPIR
crumb trail: > mpi > Performance, tools, and profiling > MPIR
MPIR is the informally specified debugging interface for processes acquisition and message queue extraction.
15.7 Determinism
crumb trail: > mpi > Determinism
MPI processes are only synchronized to a certain extent, so you may wonder what guarantees there are that running a code twice will give the same result. You need to consider two cases: first of all, if the two runs are on different numbers of processors there are already numerical problems; see Eijkhout:IntroHPC .
Let us then limit ourselves to two runs on the same set of processors. In that case, MPI is deterministic as long as you do not use wildcards such as MPI_ANY_SOURCE . Formally, MPI messages are `nonovertaking': two messages between the same sender-receiver pair will arrive in sequence. Actually, they may not arrive in sequence: they are matched in sequence in the user program. If the second message is much smaller than the first, it may actually arrive earlier in the lower transport layer.
15.8 Subtleties with processor synchronization
crumb trail: > mpi > Subtleties with processor synchronization
Blocking communication involves a complicated dialog between the two processors involved. Processor one says `I have this much data to send; do you have space for that?', to which processor two replies `yes, I do; go ahead and send', upon which processor one does the actual send. This back-and-forth (technically known as a handshake ) takes a certain amount of communication overhead. For this reason, network hardware will sometimes forgo the handshake for small messages, and just send them regardless, knowing that the other process has a small buffer for such occasions.
One strange side-effect of this strategy is that a code that should deadlock according to the MPI specification does not do so. In effect, you may be shielded from you own programming mistake! Of course, if you then run a larger problem, and the small message becomes larger than the threshold, the deadlock will suddenly occur. So you find yourself in the situation that a bug only manifests itself on large problems, which are usually harder to debug. In this case, replacing every MPI_Send with a MPI_Ssend will force the handshake, even for small messages.
Conversely, you may sometimes wish to avoid the handshake on large messages. MPI as a solution for this: the MPI_Rsend (`ready send') routine sends its data immediately, but it needs the receiver to be ready for this. How can you guarantee that the receiving process is ready? You could for instance do the following (this uses nonblocking routines, which are explained below in section 4.2.1 ):
if ( receiving ) {
MPI_Irecv() // post nonblocking receive
MPI_Barrier() // synchronize
else if ( sending ) {
MPI_Barrier() // synchronize
MPI_Rsend() // send data fast
When the barrier is reached, the receive has been posted, so it is safe
to do a ready send. However, global barriers are not a good idea.
Instead you would just synchronize the two processes involved.
Exercise
Give pseudo-code for a scheme where you synchronize the two
processes through the exchange of a blocking zero-size message.
End of exercise
15.9 Shell interaction
crumb trail: > mpi > Shell interaction
MPI programs are not run directly from the shell, but are started through an ssh tunnel . We briefly discuss ramifications of this.
15.9.1 Standard input
crumb trail: > mpi > Shell interaction > Standard input
Letting MPI processes interact with the environment is not entirely straightforward. For instance, shell input redirection as in
mpiexec -n 2 mpiprogram < someinputmay not work.
Instead, use a script programscript that has one parameter:
#!/bin/bash mpirunprogram < $1and run this in parallel:
mpiexec -n 2 programscript someinput
15.9.2 Standard out and error
crumb trail: > mpi > Shell interaction > Standard out and error
The stdout and stderr streams of an MPI process are returned through the ssh tunnel. Thus they can be caught as the stdout/err of mpiexec .
// outerr.c fprintf(stdout,"This goes to std out\n"); fprintf(stderr,"This goes to std err\n");
The name of the variable is implementation dependent, for mpich and its derivates such as Intel MPI it is PMI_RANK . (There is a similar PMI_SIZE .)
If you are only interested in displaying the rank
- srun has an option --label .
15.9.3 Process status
crumb trail: > mpi > Shell interaction > Process status
The return code of MPI_Abort is returned as the processes status of {mpiexec}. Running
// abort.c if (procno==nprocs-1) MPI_Abort(comm,37);
mpiexec -n 4 ./abort ; \
echo "Return code from ${MPIRUN} is <<$$?>>"
gives
TACC: Starting up job 3760534 TACC: Starting parallel tasks... application called MPI_Abort(MPI_COMM_WORLD, 37) - process 3 TACC: MPI job exited with code: 37 TACC: Shutdown complete. Exiting. Return code from ibrun is <<37>>
15.9.4 Multiple program start
crumb trail: > mpi > Shell interaction > Multiple program start
If the MPI application consists of sub-applications, that is, if we have a true MPMD runs, there are usually two ways of starting this up. (Once started, each process can retrieve with MPI_APPNUM to which application it belongs.)
The first possibility is that the job starter, mpiexec or mpirun or a local variant, accepts multiple executables:
mpiexec spec0 [ : spec1 [ : spec2 : ... ] ]
Absent this mechanism, the sort of script of section 15.9.1 can also be used to implement MPMD runs. We let the script start one of a number of programs, and we use the fact that the MPI rank is known in the environment; see section 15.9.2 .
Use a script mpmdscript :
#!/bin/bashrank=$PMI_RANK half=$(( ${PMI_SIZE} / 2 ))
if [ $rank -lt $half ] ; then ./prog1 else ./prog2 fi
TACC: Starting up job 4032931 TACC: Starting parallel tasks... Program 1 has process 1 out of 4 Program 2 has process 2 out of 4 Program 2 has process 3 out of 4 Program 1 has process 0 out of 4 TACC: Shutdown complete. Exiting.
This script is run in parallel:
mpiexec -n 25 mpmdscript
15.10 Leftover topics
crumb trail: > mpi > Leftover topics
15.10.1 MPI constants
crumb trail: > mpi > Leftover topics > MPI constants
MPI has a number of built-in constants . These do not all behave the same.
- Some are compile-time constants. Examples are MPI_VERSION and MPI_MAX_PROCESSOR_NAME . Thus, they can be used in array size declarations, even before MPI_Init .
- Some link-time constants get their value by MPI initialization, such as MPI_COMM_WORLD . Such symbols, which include all predefined handles, can be used in initialization expressions.
- Some link-time symbols can not be used in initialization expressions, such as MPI_BOTTOM and MPI_STATUS_IGNORE .
For symbols, the binary realization is not defined. For instance, MPI_COMM_WORLD is of type MPI_Comm , but the implementation of that type is not specified.
See Annex A of the MPI-3.1 standard for full lists.
The following are the compile-time constants:
- MPI_MAX_PROCESSOR_NAME
- MPI_MAX_LIBRARY_VERSION_STRING
- MPI_MAX_ERROR_STRING
- MPI_MAX_DATAREP_STRING
- MPI_MAX_INFO_KEY
- MPI_MAX_INFO_VAL
- MPI_MAX_OBJECT_NAME
- MPI_MAX_PORT_NAME
- MPI_VERSION
- MPI_SUBVERSION
Fortran note
- MPI_STATUS_SIZE . No longer needed with Fortran2008 support; see section 4.3 .
- MPI_ADDRESS_KIND
- MPI_COUNT_KIND
- MPI_INTEGER_KIND
- MPI_OFFSET_KIND
- MPI_SUBARRAYS_SUPPORTED
- MPI_ASYNC_PROTECTS_NONBLOCKING
The following are the link-time constants:
- MPI_BOTTOM
- MPI_STATUS_IGNORE
- MPI_STATUSES_IGNORE
- MPI_ERRCODES_IGNORE
- MPI_IN_PLACE
- MPI_ARGV_NULL
- MPI_ARGVS_NULL
- MPI_UNWEIGHTED
- MPI_WEIGHTS_EMPTY
Assorted constants:
- MPI_PROC_NULL and other ..._NULL constants.
- MPI_ANY_SOURCE
- MPI_ANY_TAG
- MPI_UNDEFINED
- MPI_BSEND_OVERHEAD
- MPI_KEYVAL_INVALID
- MPI_LOCK_EXCLUSIVE
- MPI_LOCK_SHARED
- MPI_ROOT
(This section was inspired by
http://blogs.cisco.com/performance/mpi-outside-of-c-and-fortran .)
15.10.2 Cancelling messages
crumb trail: > mpi > Leftover topics > Cancelling messages
In section 4.3.1 we showed a master-worker example where the master accepts in arbitrary order the messages from the workers. Here we will show a slightly more complicated example, where only the result of the first task to complete is needed. Thus, we issue an MPI_Recv with MPI_ANY_SOURCE as source. When a result comes, we broadcast its source to all processes. All the other workers then use this information to cancel their message with an MPI_Cancel operation.
// cancel.c
fprintf(stderr,"get set, go!\n");
if (procno==nprocs-1) {
MPI_Status status;
MPI_Recv(dummy,0,MPI_INT, MPI_ANY_SOURCE,0,comm,
&status);
first_tid = status.MPI_SOURCE;
MPI_Bcast(&first_tid,1,MPI_INT, nprocs-1,comm);
fprintf(stderr,"[%d] first msg came from %d\n",procno,first_tid);
} else {
float randomfraction = (rand() / (double)RAND_MAX);
int randomwait = (int) ( nprocs * randomfraction );
MPI_Request request;
fprintf(stderr,"[%d] waits for %e/%d=%d\n",
procno,randomfraction,nprocs,randomwait);
sleep(randomwait);
MPI_Isend(dummy,0,MPI_INT, nprocs-1,0,comm,
&request);
MPI_Bcast(&first_tid,1,MPI_INT, nprocs-1,comm
);
if (procno!=first_tid) {
MPI_Cancel(&request);
fprintf(stderr,"[%d] canceled\n",procno);
}
}
After the cancelling operation it is still necessary to call MPI_Request_free , MPI_Wait , or MPI_Test in order to free the request object.
The MPI_Cancel operation is local, so it can not be used for nonblocking collectives or one-sided transfers.
Remark
As of MPI-3.2, cancelling a send is deprecated.
End of remark
15.10.3 The origin of one-sided communication in ShMem
crumb trail: > mpi > Leftover topics > The origin of one-sided communication in ShMem
The Cray T3E had a library called shmem which offered a type of shared memory. Rather than having a true global address space it worked by supporting variables that were guaranteed to be identical between processors, and indeed, were guaranteed to occupy the same location in memory. Variables could be declared to be shared a `symmetric' pragma or directive; their values could be retrieved or set by shmem_get and shmem_put calls.
15.11 Literature
crumb trail: > mpi > Literature
Online resources:
-
MPI 1 Complete reference:
http://www.netlib.org/utk/papers/mpi-book/mpi-book.html -
Official MPI documents:
http://www.mpi-forum.org/docs/ -
List of all MPI routines:
http://www.mcs.anl.gov/research/projects/mpi/www/www3/
Tutorial books on MPI:
- Using MPI [Gropp:UsingMPI1] by some of the original authors.