MPI topic: File I/O
Experimental html version of Parallel Programming in MPI, OpenMP, and PETSc by Victor Eijkhout. download the textbook at https:/theartofhpc.com/pcse
10.2 : File reading and writing
10.2.1 : Nonblocking read/write
10.2.2 : Individual file pointers, contiguous writes
10.2.3 : File views
10.2.4 : Shared file pointers
10.3 : Consistency
10.4 : Constants
10.5 : Error handling
10.6 : Review questions
Back to Table of Contents
10 MPI topic: File I/O
This chapter discusses the I/O support of MPI, which is intended to alleviate the problems inherent in parallel file access. Let us first explore the issues. This story partly depends on what sort of parallel computer are you running on. Here are some of the hardware scenarios you may encounter:
- On networks of workstations each node will have a separate drive with its own file system.
- On many clusters there will be a shared file system that acts as if every process can access every file.
- Cluster nodes may or may not have a private file system.
Based on this, the following strategies are possible, even before we start talking about MPI I/O.
- One process can collect all data with MPI_Gather and write it out. There are at least three things wrong with this: it uses network bandwidth for the gather, it may require a large amount of memory on the root process, and centralized writing is a bottleneck.
- Absent a shared file system, writing can be parallelized by letting every process create a unique file and merge these after the run. This makes the I/O symmetric, but collecting all the files is a bottleneck.
- Even with a with a shared file system this approach is possible, but it can put a lot of strain on the file system, and the post-processing can be a significant task.
- Using a shared file system, there is nothing against every process opening the same existing file for reading, and using an individual file pointer to get its unique data.
- \ldots but having every process open the same file for output is probably not a good idea. For instance, if two processes try to write at the end of the file, you may need to synchronize them, and synchronize the file system flushes.
For these reasons, MPI has a number of routines that make it possible to read and write a single file from a large number of processes, giving each process its own well-defined location where to access the data. These locations can use MPI derived datatype s for both the source data (that is, in memory) and target data (that is, on disk). Thus, in one call that is collective on a communicator each process can address data that is not contiguous in memory, and place it in locations that are not contiguous on disc.
There are dedicated libraries for file I/O, such as hdf5 , netcdf , or silo . However, these often add header information to a file that may not be understandable to post-processing applications. With MPI I/O you are in complete control of what goes to the file. (A useful tool for viewing your file is the unix utility od .)
TACC note Each node has a private /tmp file system (typically flash storage), to which you can write files. Considerations:
- Since these drives are separate from the shared file system, you don't have to worry about stress on the file servers.
- These temporary file systems are wiped after your job finishes, so you have to do the post-processing in your job script.
- The capacity of these local drives are fairly limited; see the userguide for exact numbers.
10.1 File handling
crumb trail: > mpi-io > File handling
MPI has a datatype for files: MPI_File . This acts a little like a traditional file handle, in that there are open, close, read/write, and seek operations on it. However, unlike traditional file handling, which in parallel would mean having one handle per process, this handle is collective: MPI processes act as if they share one file handle.
You open a file with MPI_File_open . This routine is collective, even if only certain processes will access the file with a read or write call. Similarly, MPI_File_close is collective.
Python note Note the slightly unusual syntax for opening a file:
mpifile = MPI.File.Open(comm,filename,mode)Even though the file is opened on a communicator, it is a class method for the MPI.File class, rather than for the communicator object. The latter is passed in as an argument.
File access modes:
- MPI_MODE_RDONLY : read only,
- MPI_MODE_RDWR : reading and writing,
- MPI_MODE_WRONLY : write only,
- MPI_MODE_CREATE : create the file if it does not exist,
- MPI_MODE_EXCL : error if creating file that already exists,
- MPI_MODE_DELETE_ON_CLOSE : delete file on close,
- MPI_MODE_UNIQUE_OPEN : file will not be concurrently opened elsewhere,
- MPI_MODE_SEQUENTIAL : file will only be accessed sequentially,
- MPI_MODE_APPEND : set initial position of all file pointers to end of file.
As a small illustration: \csnippetwithoutput{mpifilebasic}{examples/mpi/c}{write}
You can delete a file with MPI_File_delete .
Buffers can be flushed with MPI_File_sync , which is a collective call.
10.2 File reading and writing
crumb trail: > mpi-io > File reading and writing
The basic file operations, in between the open and close calls, are the POSIX-like, noncollective, calls
-
MPI_File_seek
. The
whence
parameter can be:
- MPI_SEEK_SET The pointer is set to offset.
- MPI_SEEK_CUR The pointer is set to the current pointer position plus offset.
- MPI_SEEK_END The pointer is set to the end of the file plus offset.
- MPI_File_write . This routine writes the specified data in the locations specified with the current file view. The number of items written is returned in the MPI_Status argument; all other fields of this argument are undefined. It can not be used if the file was opened with MPI_MODE_SEQUENTIAL .
- If all processes execute a write at the same logical time, it is better to use the collective call MPI_File_write_all .
- MPI_File_read This routine attempts to read the specified data from the locations specified in the current file view. The number of items read is returned in the MPI_Status argument; all other fields of this argument are undefined. It can not be used if the file was opened with MPI_MODE_SEQUENTIAL .
- If all processes execute a read at the same logical time, it is better to use the collective call MPI_File_read_all .
For thread safety it is good to combine seek and read/write operations:
- MPI_File_read_at : combine read and seek. The collective variant is MPI_File_read_at_all .
- MPI_File_write_at : combine write and seek. The collective variant is MPI_File_write_at_all ; section 10.2.2 .
Writing to and reading from a parallel file is rather similar to sending a receiving:
- The process uses an predefined data type or a derived datatype to describe what elements in an array go to file, or are read from file.
- In the simplest case, your read or write that data to the file using an offset, or first having done a seek operation.
- But you can also set a `file view' to describe explicitly what elements in the file will be involved.
10.2.1 Nonblocking read/write
crumb trail: > mpi-io > File reading and writing > Nonblocking read/write
Just like there are blocking and nonblocking sends, there are also nonblocking writes and reads: MPI_File_iwrite , MPI_File_iread operations, and their collective versions MPI_File_iwrite_all , MPI_File_iread_all .
Also MPI_File_iwrite_at , MPI_File_iwrite_at_all , MPI_File_iread_at ., MPI_File_iread_at_all .
These routines output an MPI_Request object, which can then be tested with MPI_Wait or MPI_Test .
Nonblocking collective I/O functions much like other nonblocking collectives (section 3.11 ): the request is satisfied if all processes finish the collective.
There are also split collective s that function like nonblocking collective I/O, but with the request/wait mechanism: MPI_File_write_all_begin / MPI_File_write_all_end (and similarly MPI_File_read_all_begin / MPI_File_read_all_end ) where the second routine blocks until the collective write/read has been concluded.
Also MPI_File_iread_shared , MPI_File_iwrite_shared .
10.2.2 Individual file pointers, contiguous writes
crumb trail: > mpi-io > File reading and writing > Individual file pointers, contiguous writes
After the collective open call, each process holds an individual file pointer that it can individually position somewhere in the shared file. Let's explore this modality.
The simplest way of writing a data to file is much like a send call: a buffer is specified with the usual count/datatype specification, and a target location in the file is given. The routine MPI_File_write_at gives this location in absolute terms with a parameter of type MPI_Offset , which counts bytes.
FIGURE 10.1: Writing at an offset
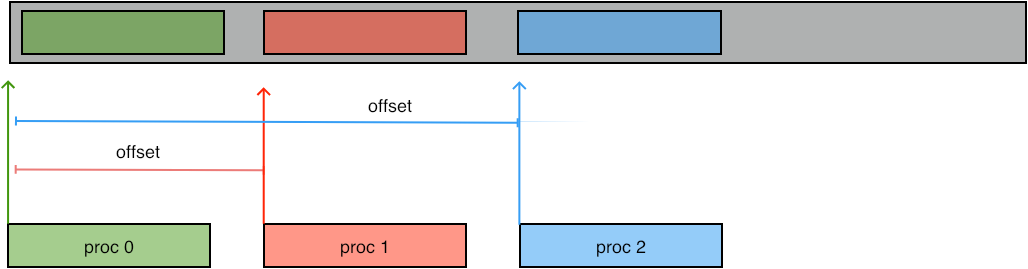
Exercise
Create a buffer of length
nwords=3
on each process, and write
these buffers as a sequence to one file with
MPI_File_write_at
.
(There is a skeleton code blockwrite in the repository)
End of exercise
Instead of giving the position in the file explicitly, you can also use a MPI_File_seek call to position the file pointer, and write with MPI_File_write at the pointer location. The write call itself also advances the file pointer so separate calls for writing contiguous elements need no seek calls with MPI_SEEK_CUR .
Exercise
Rewrite the code of exercise
10.1
to
use a loop where each iteration
writes only one item to file.
Note that no explicit advance of the file pointer is needed.
End of exercise
Exercise Construct a file with the consecutive integers $0,\ldots,WP$ where $W$ some integer, and $P$ the number of processes. Each process $p$ writes the numbers $p,p+W,p+2W,\ldots$. Use a loop where each iteration
- writes a single number with MPI_File_write , and
- advanced the file pointer with MPI_File_seek with a whence parameter of MPI_SEEK_CUR .
End of exercise
10.2.3 File views
crumb trail: > mpi-io > File reading and writing > File views
The previous mode of writing is enough for writing simple contiguous blocks in the file. However, you can also access noncontiguous areas in the file. For this you use MPI_File_set_view . This call is collective, even if not all processes access the file.
- The disp displacement parameters is measured in bytes. It can differ between processes. On sequential files such as tapes or network streams it does not make sense to set a displacement; for those the MPI_DISPLACEMENT_CURRENT value can be used.
- The etype describes the data type of the file, it needs to be the same on all processes.
- The filetype describes how this process sees the file, so it can differ between processes.
-
The
datarep
string can have the following values:
- native : data on disk is represented in exactly the same format as in memory;
- internal : data on disk is represented in whatever internal format is used by the MPI implementation;
- external : data on disk is represented using XDR portable data formats.
- The info parameter is an MPI_Info object, or MPI_INFO_NULL . See section 15.1.1.3 for more on file info. (See T3PIO [t3pio-git] for a tool that assists in setting this object.)
// scatterwrite.c MPI_File_set_view (mpifile, offset,MPI_INT,scattertype, "native",MPI_INFO_NULL);
FIGURE 10.2: Writing at a view
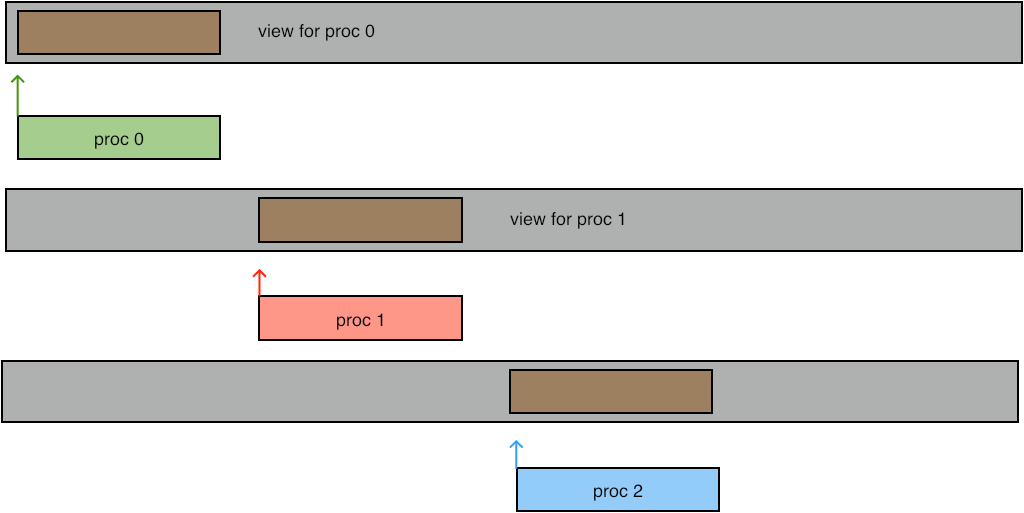
Exercise
(There is a skeleton code viewwrite in the repository)
Write a file in the same way as in exercise
10.1
,
but now use
MPI_File_write
and use
MPI_File_set_view
to set
a view that determines where the data is written.
End of exercise
You can get very creative effects by setting the view to a derived datatype.
FIGURE 10.3: Writing at a derived type
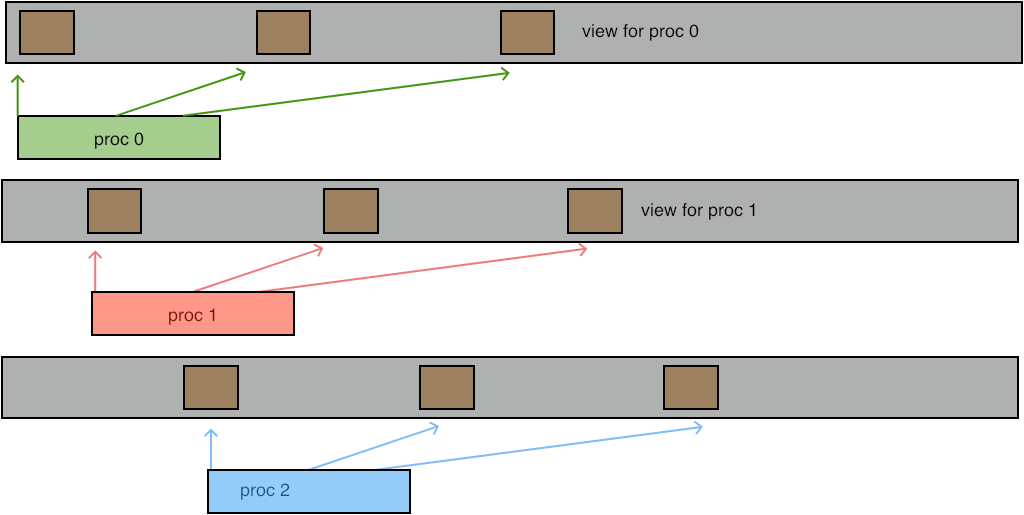
Fortran note In Fortran you have to assure that the displacement parameter is of `kind' MPI_OFFSET_KIND . In particular, you can not specify a literal zero `0' as the displacement; use 0_MPI_OFFSET_KIND instead. End of Fortran note
More: MPI_File_set_size , MPI_File_get_size MPI_File_preallocate , MPI_File_get_view .
10.2.4 Shared file pointers
crumb trail: > mpi-io > File reading and writing > Shared file pointers
It is possible to have a file pointer that is shared (and therefore identical) between all processes of the communicator that was used to open the file. This file pointer is set with MPI_File_seek_shared . For reading and writing there are then two sets of routines:
- Individual accesses are done with MPI_File_read_shared and MPI_File_write_shared . Nonblocking variants are MPI_File_iread_shared and MPI_File_iwrite_shared .
- Collective accesses are done with MPI_File_read_ordered and MPI_File_write_ordered , which execute the operations in order ascending by rank.
Shared file pointers require that the same view is used on all processes. Also, these operations are less efficient because of the need to maintain the shared pointer.
10.3 Consistency
crumb trail: > mpi-io > Consistency
It is possible for one process to read data previously writte by another process. For this, it is of course necessary to impose a temporal order, for instance by using MPI_Barrier , or using a zero-byte send from the writing to the reading process.
However, the file also needs to be declared atomic MPI_File_set_atomicity .
10.4 Constants
crumb trail: > mpi-io > Constants
MPI_SEEK_SET used to be called SEEK_SET which gave conflicts with the C++ library. This had to be circumvented with
make CPPFLAGS="-DMPICH_IGNORE_CXX_SEEK -DMPICH_SKIP_MPICXX"and such.
10.5 Error handling
crumb trail: > mpi-io > Error handling
By default, MPI uses MPI_ERRORS_ARE_FATAL since parallel errors are almost impossible to recover from. File handling errors, on the other hand, are less serious: if a file is not found, the operation can be abandoned. For this reason, the default error handler for file operations is MPI_ERRORS_RETURN .
The default I/O error handler can be queried and set with MPI_File_get_errhandler and MPI_File_set_errhandler respectively, passing MPI_FILE_NULL as argument.
\newpage
10.6 Review questions
crumb trail: > mpi-io > Review questions
Exercise T/F? File views ( MPI_File_set_view ) are intended to
- write MPI derived types to file; without them you can only write contiguous buffers;
- prevent collisions in collective writes; they are not needed for individual writes.
End of exercise
Exercise
The sequence
MPI_File_seek_shared
,
MPI_File_read_shared
can be replaced by
MPI_File_seek
,
MPI_File_read
if you make what changes?
End of exercise