MPI topic: Communication modes
Experimental html version of Parallel Programming in MPI, OpenMP, and PETSc by Victor Eijkhout. download the textbook at https:/theartofhpc.com/pcse
5.1.1 : Persistent point-to-point communication
5.1.2 : Persistent collectives
5.1.3 : Persistent neighbor communications
5.2 : Partitioned communication
5.3 : Synchronous and asynchronous communication
5.3.1 : Synchronous send operations
5.4 : Local and nonlocal operations
5.5 : Buffered communication
5.5.1 : Buffer treatment
5.5.2 : Buffered send calls
Back to Table of Contents
5 MPI topic: Communication modes
5.1 Persistent communication
crumb trail: > mpi-persist > Persistent communication
You can imagine that setting up a communication carries some overhead, and if the same communication structure is repeated many times, this overhead may be avoided.
Persistent communication is a mechanism for dealing with a repeating communication transaction, where the parameters of the transaction, such as sender, receiver, tag, root, and buffer address /type / size, stay the same. Only the contents of the buffers involved may change between the transactions.
- For nonblocking communications MPI_Ixxx (both point-to-point and collective) there is a persistent variant MPI_Xxx_init with the same calling sequence. The `init' call produces an MPI_Request output parameter, which can be used to test for completion of the communication.
- The `init' routine does not start the actual communication: that is done in MPI_Start , or MPI_Startall for multiple requests.
- Any of the MPI `wait' calls can then be used to conclude the communication.
- The communication can then be restarted with another `start' call.
- The wait call does not release the request object, since it can be used for repeat occurrences of this transaction. The request object is only freed with MPI_Request_free .
MPI_Send_init( /* ... */ &request);
while ( /* ... */ ) {
MPI_Start( request );
MPI_Wait( request, &status );
}
MPI_Request_free( & request );
MPL note MPL returns a prequest from persistent `init' routines, rather than an irequest (MPL note 4.2.2 ):
template<typename T > prequest send_init (const T &data, int dest, tag t=tag(0)) const;Likewise, there is a prequest_pool instead of an irequest_pool (note 4.2.2.3 ). End of MPL note
5.1.1 Persistent point-to-point communication
crumb trail: > mpi-persist > Persistent communication > Persistent point-to-point communication
The main persistent point-to-point routines are MPI_Send_init , which has the same calling sequence as MPI_Isend , and MPI_Recv_init , which has the same calling sequence as MPI_Irecv .
In the following example a ping-pong is implemented with persistent communication. Since we use persistent operations for both send and receive on the `ping' process, we use MPI_Startall to start both at the same time, and MPI_Waitall to test their completion. (There is MPI_Start for starting a single persistent transfer.) { \def\snippetcodefraction{.45} \def\snippetlistfraction{.5} \csnippetwithoutput{persist}{examples/mpi/c}{persist} }
(Ask yourself: why does the sender use MPI_Startall and MPI_Waitall , but the receiver uses MPI_Start and MPI_Wait twice?)
## persist.py
requests = [ None ] * 2
sendbuf = np.ones(size,dtype=int)
recvbuf = np.ones(size,dtype=int)
if procid==src:
print("Size:",size)
times[isize] = MPI.Wtime()
for n in range(nexperiments):
requests[0] = comm.Isend(sendbuf[0:size],dest=tgt)
requests[1] = comm.Irecv(recvbuf[0:size],source=tgt)
MPI.Request.Waitall(requests)
sendbuf[0] = sendbuf[0]+1
times[isize] = MPI.Wtime()-times[isize]
elif procid==tgt:
for n in range(nexperiments):
comm.Recv(recvbuf[0:size],source=src)
comm.Send(recvbuf[0:size],dest=src)
As with ordinary send commands, there are persistent variants of the other send modes:
- MPI_Bsend_init for buffered communication, section 5.5 ;
- MPI_Ssend_init for synchronous communication, section 5.3.1 ;
- MPI_Rsend_init for ready sends, section 15.8 .
5.1.2 Persistent collectives
crumb trail: > mpi-persist > Persistent communication > Persistent collectives
\begin{mpifournote} {Persistent collectives}
For each collective call, there is a persistent variant. As with persistent point-to-point calls (section 5.1.1 ), these have largely the same calling sequence as the nonpersistent variants, except for:
- an MPI_Info parameter that can be used to pass system-dependent hints; and
- an added final MPI_Request parameter.
// powerpersist1.c
double localnorm,globalnorm=1.;
MPI_Request reduce_request;
MPI_Allreduce_init
( &localnorm,&globalnorm,1,MPI_DOUBLE,MPI_SUM,
comm,MPI_INFO_NULL,&reduce_request);
for (int it=0; ; it++) {
/*
* Matrix vector product
*/
matmult(indata,outdata,buffersize);
// start computing norm of output vector
localnorm = local_l2_norm(outdata,buffersize);
double old_globalnorm = globalnorm;
MPI_Start( &reduce_request );
// end computing norm of output vector
MPI_Wait( &reduce_request,MPI_STATUS_IGNORE );
globalnorm = sqrt(globalnorm);
// now `globalnorm' is the L2 norm of `outdata'
scale(outdata,indata,buffersize,1./globalnorm);
}
MPI_Request_free( &reduce_request );
Some points.
- Metadata arrays, such as of counts and datatypes, must not be altered until the MPI_Request_free call.
- The initialization call is nonlocal (for this particular case of persistent collectives), so it can block until all processes have performed it.
-
Multiple persistent collective can be initialized, in which case
they satisfy the same restrictions as ordinary collectives, in particular
on ordering. Thus, the following code is incorrect:
// WRONG if (procid==0) { MPI_Reduce_init( /* ... */ &req1); MPI_Bcast_init( /* ... */ &req2); } else { MPI_Bcast_init( /* ... */ &req2); MPI_Reduce_init( /* ... */ &req1); }However, after initialization the start calls can be in arbitrary order, and in different order among the processes.
\begin{raggedlist} Available persistent collectives are: MPI_Barrier_init MPI_Bcast_init MPI_Reduce_init MPI_Allreduce_init MPI_Reduce_scatter_init MPI_Reduce_scatter_block_init MPI_Gather_init MPI_Gatherv_init MPI_Allgather_init MPI_Allgatherv_init MPI_Scatter_init MPI_Scatterv_init MPI_Alltoall_init MPI_Alltoallv_init MPI_Alltoallw_init MPI_Scan_init MPI_Exscan_init \end{raggedlist}
\end{mpifournote}
5.1.3 Persistent neighbor communications
crumb trail: > mpi-persist > Persistent communication > Persistent neighbor communications
\begin{mpifournote} {Neighborhood collectives, init}
There are persistent version of the neighborhood collectives; section 11.2.2 .
\begin{raggedlist} MPI_Neighbor_allgather_init , MPI_Neighbor_allgatherv_init , MPI_Neighbor_alltoall_init , MPI_Neighbor_alltoallv_init , MPI_Neighbor_alltoallw_init , \end{raggedlist}
\end{mpifournote}
5.2 Partitioned communication
crumb trail: > mpi-persist > Partitioned communication \begin{mpifournote} {Partitioned communication}
Partitioned communication is a variant on persistent communication , in the sense that we use the init / start / wait sequence. There difference is that now a message can be constructed in bit-by-bit.
- The normal MPI_Send_init is replaced by MPI_Psend_init . Note the presence of an MPI_Info argument, as in persistent collectives, but unlike in persistent sends and receives.
- After this, the MPI_Start does not actually start the transfer; instead:
- Each partition of the message is separately declared as ready-to-be-sent with MPI_Pready .
- An MPI_Wait call completes the operation, indicating that all partitions have been sent.
Indicating that parts of a message are ready for sending is done by one of the following calls:
- MPI_Pready for a single partition;
- MPI_Pready_range for a range of partitions; and
- MPI_Pready_list for an explicitly enumerated list of partitions.
MPI_Request send_request;
MPI_Psend_init
(sendbuffer,nparts,SIZE,MPI_DOUBLE,tgt,0,
comm,MPI_INFO_NULL,&send_request);
for (int it=0; it<ITERATIONS; it++) {
MPI_Start(&send_request);
for (int ip=0; ip<nparts; ip++) {
fill_buffer(sendbuffer,partitions[ip],partitions[ip+1],ip);
MPI_Pready(ip,send_request);
}
MPI_Wait(&send_request,MPI_STATUS_IGNORE);
}
MPI_Request_free(&send_request);
The receiving side is largely the mirror image of the sending side:
double *recvbuffer = (double*)malloc(bufsize*sizeof(double));
MPI_Request recv_request;
MPI_Precv_init
(recvbuffer,nparts,SIZE,MPI_DOUBLE,src,0,
comm,MPI_INFO_NULL,&recv_request);
for (int it=0; it<ITERATIONS; it++) {
MPI_Start(&recv_request); int r=1,flag;
for (int ip=0; ip<nparts; ip++) // cycle this many times
for (int ap=0; ap<nparts; ap++) { // check specific part
MPI_Parrived(recv_request,ap,&flag);
if (flag) {
r *= chck_buffer
(recvbuffer,partitions[ap],partitions[ap+1],ap);
break; }
}
MPI_Wait(&recv_request,MPI_STATUS_IGNORE);
}
MPI_Request_free(&recv_request);
- a partitioned send can only be matched with a partitioned receive, so we start with an MPI_Precv_init .
- Arrival of a partition can be tested with MPI_Parrived .
- A call to MPI_Wait completes the operation, indicating that all partitions have arrived.
\end{mpifournote}
5.3 Synchronous and asynchronous communication
crumb trail: > mpi-persist > Synchronous and asynchronous communication
It is easiest to think of blocking as a form of synchronization with the other process, but that is not quite true. Synchronization is a concept in itself, and we talk about synchronous communication if there is actual coordination going on with the other process, and asynchronous communication if there is not. Blocking then only refers to the program waiting until the user data is safe to reuse; in the synchronous case a blocking call means that the data is indeed transferred, in the asynchronous case it only means that the data has been transferred to some system buffer.
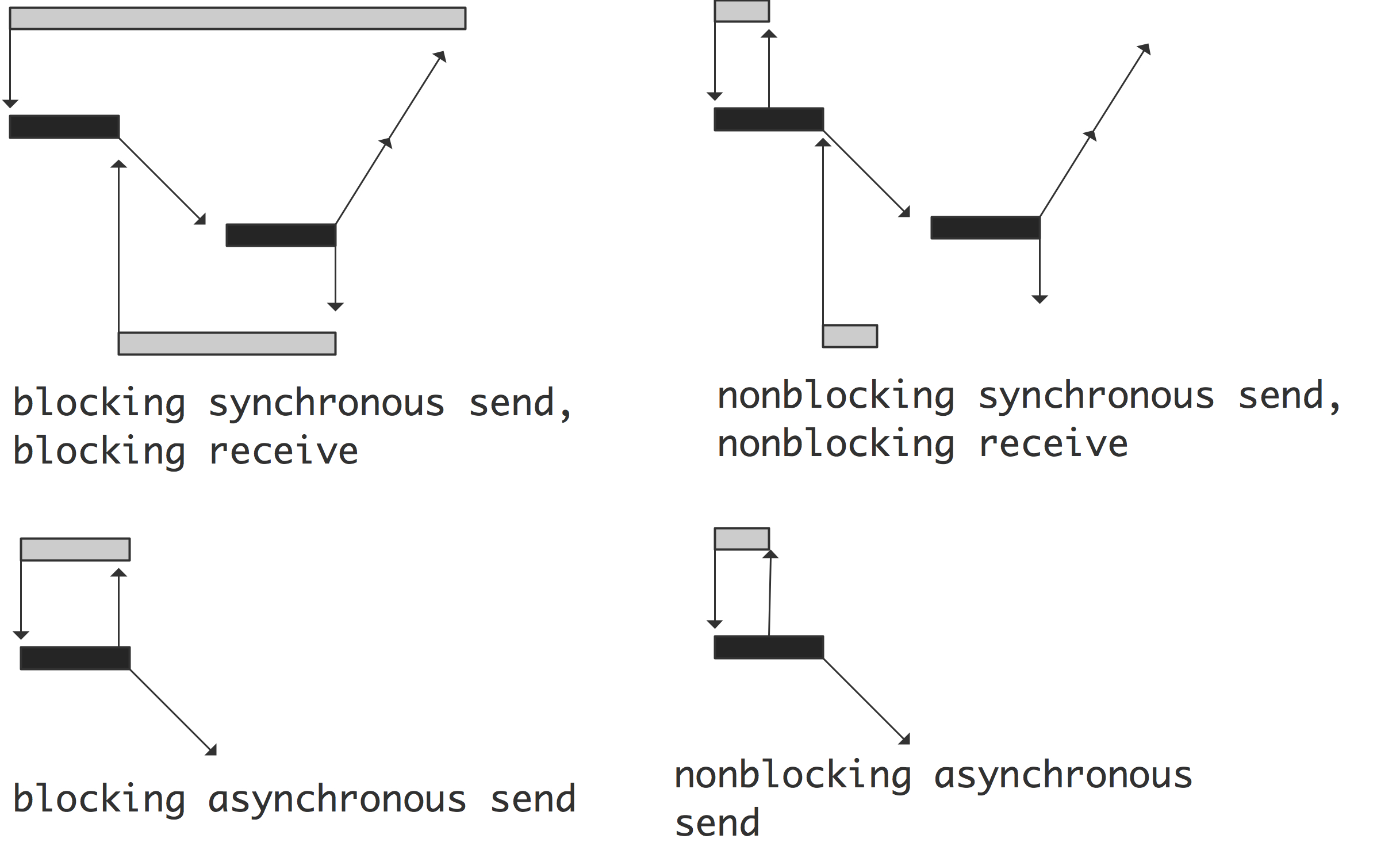
FIGURE 5.1: Blocking and synchronicity
The four possible cases are illustrated in figure 5.1 .
5.3.1 Synchronous send operations
crumb trail: > mpi-persist > Synchronous and asynchronous communication > Synchronous send operations
MPI has a number of routines for synchronous communication, such as MPI_Ssend . Driving home the point that nonblocking and asynchronous are different concepts, there is a routine MPI_Issend , which is synchronous but nonblocking. These routines have the same calling sequence as their not-explicitly synchronous variants, and only differ in their semantics.
See section 4.1.4.2 for examples.
5.4 Local and nonlocal operations
crumb trail: > mpi-persist > Local and nonlocal operations
The MPI standard does not dictate whether communication is buffered. If a message is buffered, a send call can complete, even if no corresponding send has been posted yet. See section 4.1.4.2 . Thus, in the standard communication, a send operation is nonlocal : its completion may be depend on whether the corresponding receive has been posted. A \indextermbusdef{local}{operation} is one that is not nonlocal.
On the other hand, buffered communication (routines MPI_Bsend , MPI_Ibsend , MPI_Bsend_init ; section 5.5 ) is local : the presence of an explicit buffer means that a send operation can complete no matter whether the receive has been posted.
The synchronous send (routines MPI_Ssend , MPI_Issend , MPI_Ssend_init ; section 15.8 ) is again nonlocal (even in the nonblocking variant) since it will only complete when the receive call has completed.
Finally, the ready mode send ( MPI_Rsend , MPI_Irsend ) is nonlocal in the sense that its only correct use is when the corresponding receive has been issued.
5.5 Buffered communication
crumb trail: > mpi-persist > Buffered communication
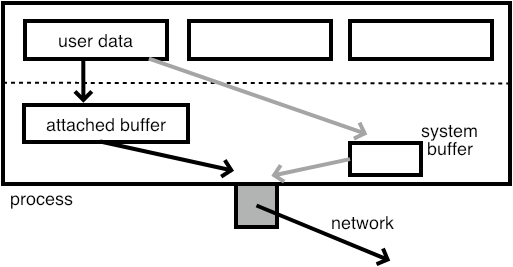
FIGURE 5.2: User communication routed through an attached buffer
By now you have probably got the notion that managing buffer space in MPI is important: data has to be somewhere, either in user-allocated arrays or in system buffers. Using buffered communication is yet another way of managing buffer space.
- You allocate your own buffer space, and you attach it to your process. This buffer is not a send buffer: it is a replacement for buffer space used inside the MPI library or on the network card; figure 5.2 . If high-bandwidth memory is available, you could create your buffer there.
- You use the MPI_Bsend (or its local variant MPI_Ibsend ) call for sending, using otherwise normal send and receive buffers;
- You detach the buffer when you're done with the buffered sends.
One advantage of buffered sends is that they are nonblocking: since there is a guaranteed buffer long enough to contain the message, it is not necessary to wait for the receiving process.
We illustrate the use of buffered sends:
// bufring.c int bsize = BUFLEN*sizeof(float); float *sbuf = (float*) malloc( bsize ), *rbuf = (float*) malloc( bsize ); MPI_Pack_size( BUFLEN,MPI_FLOAT,comm,&bsize); bsize += MPI_BSEND_OVERHEAD; float *buffer = (float*) malloc( bsize );MPI_Buffer_attach( buffer,bsize ); err = MPI_Bsend(sbuf,BUFLEN,MPI_FLOAT,next,0,comm); MPI_Recv (rbuf,BUFLEN,MPI_FLOAT,prev,0,comm,MPI_STATUS_IGNORE); MPI_Buffer_detach( &buffer,&bsize );
5.5.1 Buffer treatment
crumb trail: > mpi-persist > Buffered communication > Buffer treatment
There can be only one buffer per process, attached with MPI_Buffer_attach . Its size should be enough for all MPI_Bsend calls that are simultaneously outstanding. You can compute the needed size of the buffer with MPI_Pack_size ; see section 6.8 . Additionally, a term of MPI_BSEND_OVERHEAD is needed. See the above code fragment.
The buffer is detached with MPI_Buffer_detach . This returns the address and size of the buffer; the call blocks until all buffered messages have been delivered.
Note that both MPI_Buffer_attach and MPI_Buffer_detach have a void* argument for the buffer, but
- in the attach routine this is the address of the buffer,
- while the detach routine it is the address of the buffer pointer.
While the buffered send is nonblocking like an MPI_Isend , there is no corresponding wait call. You can force delivery by
MPI_Buffer_detach( &b, &n ); MPI_Buffer_attach( b, n );
MPL note Creating and attaching a buffer is done through bsend_buffer and a support routine bsend_size helps in calculating the buffer size:
// bufring.cxx
vector<float> sbuf(BUFLEN), rbuf(BUFLEN);
int size{ comm_world.bsend_size<float>(mpl::contiguous_layout<float>(BUFLEN)) };
mpl::bsend_buffer buff(size);
comm_world.bsend(sbuf.data(),mpl::contiguous_layout<float>(BUFLEN), next);
Constant: mpl:: bsend_overhead is \lstinline{constexpr}'d to the MPI constant MPI_BSEND_OVERHEAD . End of MPL note
MPL note There is a separate attach routine, but normally this is called by the constructor of the bsend_buffer . Likewise, the detach routine is called in the buffer destructor.
void mpl::environment::buffer_attach (void *buff, int size); std::pair< void *, int > mpl::environment::buffer_detach ();End of MPL note
5.5.2 Buffered send calls
crumb trail: > mpi-persist > Buffered communication > Buffered send calls
The possible error codes are
- MPI_SUCCESS the routine completed successfully.
- MPI_ERR_BUFFER The buffer pointer is invalid; this typically means that you have supplied a null pointer.
- MPI_ERR_INTERN An internal error in MPI has been detected.
The asynchronous version is MPI_Ibsend , the persistent (see section 5.1 ) call is MPI_Bsend_init .