MPI topic: One-sided communication
Experimental html version of Parallel Programming in MPI, OpenMP, and PETSc by Victor Eijkhout. download the textbook at https:/theartofhpc.com/pcse
9.1.1 : Window creation and freeing
9.1.2 : Address arithmetic
9.2 : Active target synchronization: epochs
9.2.1 : Fence assertions
9.2.2 : Non-global target synchronization
9.3 : Put, get, accumulate
9.3.1 : Put
9.3.2 : Get
9.3.3 : Put and get example: halo update
9.3.4 : Accumulate
9.3.5 : Ordering and coherence of RMA operations
9.3.6 : Request-based operations
9.3.7 : Atomic operations
9.3.7.1 : A case study in atomic operations
9.4 : Passive target synchronization
9.4.1 : Lock types
9.4.2 : Lock all
9.4.3 : Completion and consistency in passive target synchronization
9.4.3.1 : Local completion
9.4.3.2 : Remote completion
9.4.3.3 : Window synchronization
9.5 : More about window memory
9.5.1 : Memory models
9.5.2 : Dynamically attached memory
9.5.3 : Window usage hints
9.5.4 : Window information
9.6 : Assertions
9.7 : Implementation
9.8 : Review questions
Back to Table of Contents
9 MPI topic: One-sided communication
Above, you saw point-to-point operations of the two-sided type: they require the co-operation of a sender and receiver. This co-operation could be loose: you can post a receive with MPI_ANY_SOURCE as sender, but there had to be both a send and receive call. This two-sidedness can be limiting. Consider code where the receiving process is a dynamic function of the data:
x = f(); p = hash(x); MPI_Send( x, /* to: */ p );The problem is now: how does p know to post a receive, and how does everyone else know not to?
In this section, you will see one-sided communication routines where a process can do a `put' or `get' operation, writing data to or reading it from another processor, without that other processor's involvement.
In one-sided MPI operations, known as RMA operations in the standard, or as RDMA in other literature, there are still two processes involved: the origin , which is the process that originates the transfer, whether this is a `put' or a `get', and the target whose memory is being accessed. Unlike with two-sided operations, the target does not perform an action that is the counterpart of the action on the origin.
That does not mean that the origin can access arbitrary data on the target at arbitrary times. First of all, one-sided communication in MPI is limited to accessing only a specifically declared memory area on the target: the target declares an area of memory that is accessible to other processes. This is known as a window . Windows limit how origin processes can access the target's memory: you can only `get' data from a window or `put' it into a window; all the other memory is not reachable from other processes. On the origin there is no such limitation; any data can function as the source of a `put' or the recipient of a `get operation.
The alternative to having windows is to use distributed shared memory or virtual shared memory : memory is distributed but acts as if it shared. The so-called PGAS languages such as UPC use this model.
Within one-sided communication, MPI has two modes: active RMA and passive RMA. In active RMA , or active target synchronization , the target sets boundaries on the time period (the `epoch') during which its window can be accessed. The main advantage of this mode is that the origin program can perform many small transfers, which are aggregated behind the scenes. This would be appropriate for applications that are structured in a BSP mode with superstep s. Active RMA acts much like asynchronous transfer with a concluding MPI_Waitall .
In passive RMA , or passive target synchronization , the target process puts no limitation on when its window can be accessed. ( PGAS languages such as UPC are based on this model: data is simply read or written at will.) While intuitively it is attractive to be able to write to and read from a target at arbitrary time, there are problems. For instance, it requires a remote agent on the target, which may interfere with execution of the main thread, or conversely it may not be activated at the optimal time. Passive RMA is also very hard to debug and can lead to race conditions.
9.1 Windows
crumb trail: > mpi-onesided > Windows
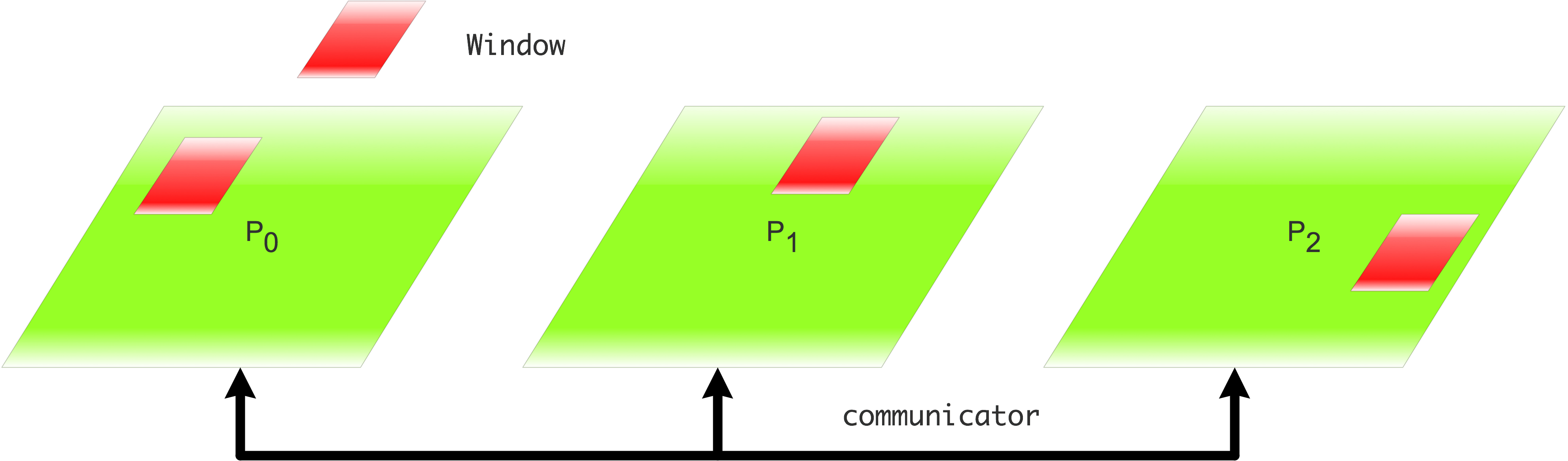
FIGURE 9.1: Collective definition of a window for one-sided data access
In one-sided communication, each processor can make an area of memory, called a window , available to one-sided transfers. This is stored in a variable of type MPI_Win . A process can put an arbitrary item from its own memory (not limited to any window) to the window of another process, or get something from the other process' window in its own memory.
A window can be characteristized as follows:
- The window is defined on a communicator, so the create call is collective; see figure 9.1 .
- The window size can be set individually on each process. A zero size is allowed, but since window creation is collective, it is not possible to skip the create call.
- You can set a `displacement unit' for the window: this is a number of bytes that will be used as the indexing unit. For example if you use sizeof(double) as the displacement unit, an MPI_Put to location 8 will go to the 8th double. That's easier than having to specify the 64th byte.
- The window is the target of data in a put operation, or the source of data in a get operation; see figure 9.2 .
- There can be memory associated with a window, so it needs to be freed explicitly with MPI_Win_free .
The typical calls involved are:
MPI_Info info; MPI_Win window; MPI_Win_allocate( /* size info */, info, comm, &memory, &window ); // do put and get calls MPI_Win_free( &window );
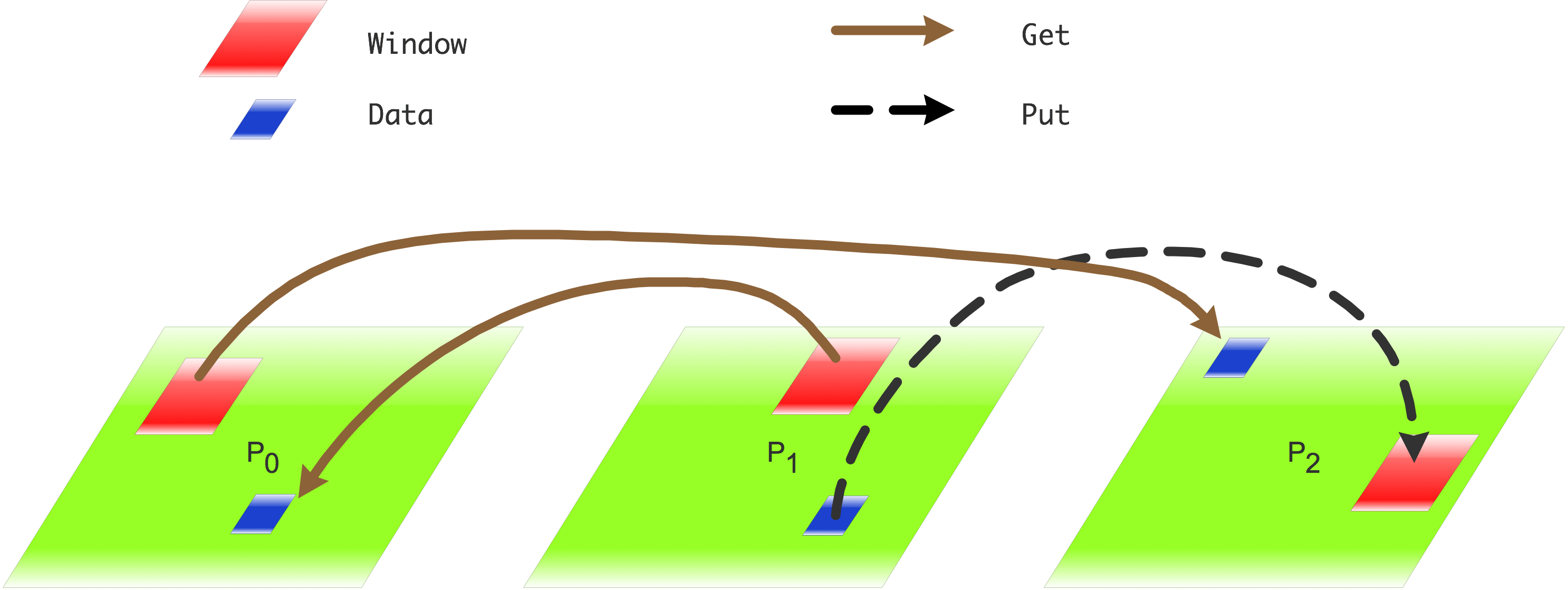
FIGURE 9.2: Put and get between process memory and windows
9.1.1 Window creation and freeing
crumb trail: > mpi-onesided > Windows > Window creation and freeing
The memory for a window is at first sight ordinary data in user space. There are multiple ways you can associate data with a window:
- You can pass a user buffer to MPI_Win_create . This buffer can be an ordinary array, or it can be created with MPI_Alloc_mem . (In the former case, it may not be possible to lock the window; section 9.4 .)
-
You can let MPI do the allocation, so that MPI can perform various
optimizations regarding placement of the memory. The user code then
receives the pointer to the data from MPI. This can again be done in two ways:
- Use MPI_Win_allocate to create the data and the window in one call.
- If a communicator is on a shared memory (see section 12.1 ) you can create a window in that shared memory with MPI_Win_allocate_shared . This will be useful for MPI shared memory ; see chapter MPI topic: Shared memory .
- Finally, you can create a window with MPI_Win_create_dynamic which postpones the allocation; see section 9.5.2 .
First of all, MPI_Win_create creates a window from a pointer to memory. The data array must not be PARAMETER or static const .
The size parameter is measured in bytes. In C this can be done with the sizeof operator;
// putfencealloc.c MPI_Win the_window; int *window_data; MPI_Win_allocate(2*sizeof(int),sizeof(int), MPI_INFO_NULL,comm, &window_data,&the_window);
Python note For computing the displacement in bytes, here is a good way for finding the size of numpy datatypes:
## putfence.py
intsize = np.dtype('int').itemsize
window_data = np.zeros(2,dtype=int)
win = MPI.Win.Create(window_data,intsize,comm=comm)
Next, one can obtain the memory from MPI by using \indexmpirep{MPI_Win_allocate}, which has the data pointer as output. Note the void* in the C signature; it is still necessary to pass a pointer to a pointer:
double *window_data; MPI_Win_allocate( ... &window_data ... );The routine MPI_Alloc_mem performs only the allocation part of MPI_Win_allocate , after which you need to MPI_Win_create .
- An error of MPI_ERR_NO_MEM indicates that no memory could be allocated. \begin{mpifournote} {Info key for alignment}
- Allocated memory can be aligned by specifying an MPI_Info key of mpi_minimum_memory_alignment . \end{mpifournote}
This memory is freed with MPI_Free_mem :
// getfence.c
int *number_buffer = NULL;
MPI_Alloc_mem
( /* size: */ 2*sizeof(int),
MPI_INFO_NULL,&number_buffer);
MPI_Win_create
( number_buffer,2*sizeof(int),sizeof(int),
MPI_INFO_NULL,comm,&the_window);
MPI_Win_free(&the_window);
MPI_Free_mem(number_buffer);
These calls reduce to malloc and free if there is no special memory area; SGI is an example where such memory does exist.
A window is freed with a call to the collective MPI_Win_free , which sets the window handle to MPI_WIN_NULL . This call must only be done if all RMA operations are concluded, by MPI_Win_fence , MPI_Win_wait , MPI_Win_complete , MPI_Win_unlock , depending on the case. If the window memory was allocated internally by MPI through a call to MPI_Win_allocate or MPI_Win_allocate_shared , it is freed. User memory used for the window can be freed after the MPI_Win_free call.
There will be more discussion of window memory in section 9.5.1 .
Python note Unlike in C, the python window allocate call does not return a pointer to the buffer memory, but an MPI.memory object. Should you need the bare memory, there are the following options:
-
Window objects expose the Python buffer interface. So you can do Pythonic things like
mview = memoryview(win) array = numpy.frombuffer(win, dtype='i4')
-
If you really want the raw base pointer (as an integer), you can do any of these:
base, size, disp_unit = win.atts base = win.Get_attr(MPI.WIN_BASE)
-
You can use mpi4py's builtin memoryview/buffer-like type, but I
do not recommend it, much better to use NumPy as above:
mem = win.tomemory() # type(mem) is MPI.memory, similar to memoryview, but quite limited in functionality base = mem.address size = mem.nbytes
9.1.2 Address arithmetic
crumb trail: > mpi-onesided > Windows > Address arithmetic
Working with windows involves a certain amount of arithmetic on addresses, meaning MPI_Aint . See MPI_Aint_add and MPI_Aint_diff in section 6.2.4 .
9.2 Active target synchronization: epochs
crumb trail: > mpi-onesided > Active target synchronization: epochs
One-sided communication has an obvious complication over two-sided: if you do a put call instead of a send, how does the recipient know that the data is there? This process of letting the target know the state of affairs is called `synchronization', and there are various mechanisms for it. First of all we will consider \indexterm{active target synchronization}. Here the target knows when the transfer may happen (the communication epoch ), but does not do any data-related calls.
In this section we look at the first mechanism, which is to use a fence operation: MPI_Win_fence . This operation is collective on the communicator of the window. (Another, more sophisticated mechanism for active target synchronization is discussed in section 9.2.2 .)
The interval between two fences is known as an epoch . Roughly speaking, in an epoch you can make one-sided communication calls, and after the concluding fence all these communications are concluded.
MPI_Win_fence(0,win); MPI_Get( /* operands */, win); MPI_Win_fence(0, win); // the `got' data is availableIn between the two fences the window is exposed, and while it is you should not access it locally. If you absolutely need to access it locally, you can use an RMA operation for that. Also, there can be only one remote process that does a put ; multiple accumulate accesses are allowed.
Fences are, together with other window calls, collective operations. That means they imply some amount of synchronization between processes. Consider:
MPI_Win_fence( ... win ... ); // start an epoch if (mytid==0) // do lots of work MPI_Win_fence( ... win ... ); // end the epochand assume that all processes execute the first fence more or less at the same time. The zero process does work before it can do the second fence call, but all other processes can call it immediately. However, they can not finish that second fence call until all one-sided communication is finished, which means they wait for the zero process.
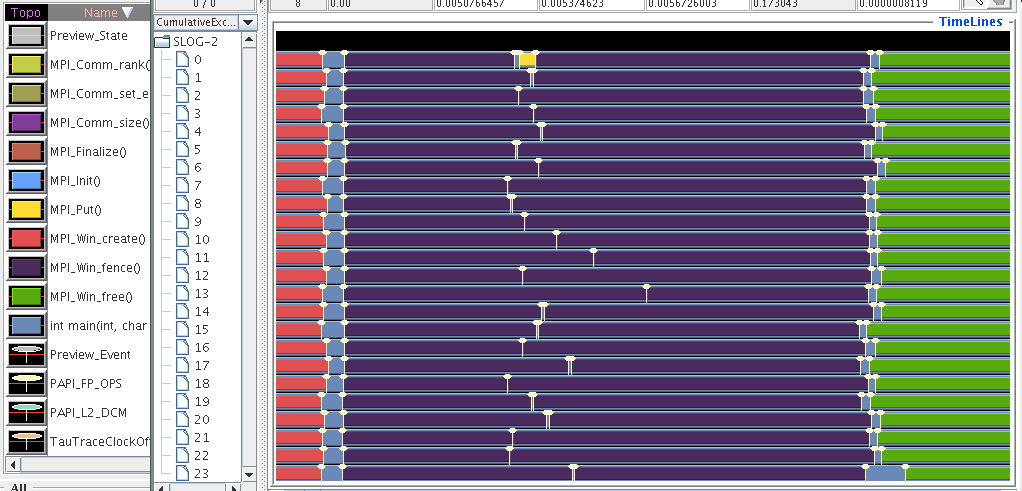 \caption{A trace of a one-sided communication epoch where process zero only originates
a one-sided transfer}
\caption{A trace of a one-sided communication epoch where process zero only originates
a one-sided transfer}
As a further restriction, you can not mix MPI_Get with MPI_Put or MPI_Accumulate calls in a single epoch. Hence, we can characterize an epoch as an access epoch on the origin, and as an exposure epoch on the target.
9.2.1 Fence assertions
crumb trail: > mpi-onesided > Active target synchronization: epochs > Fence assertions
You can give various hints to the system about this epoch versus the ones before and after through the assert parameter.
- MPI_MODE_NOSTORE This value can be specified or not per process.
- MPI_MODE_NOPUT This value can be specified or not per process.
- MPI_MODE_NOPRECEDE This value has to be specified or not the same on all processes.
- MPI_MODE_NOSUCCEED This value has to be specified or not the same on all processes.
Example:
MPI_Win_fence((MPI_MODE_NOPUT | MPI_MODE_NOPRECEDE), win); MPI_Get( /* operands */, win); MPI_Win_fence(MPI_MODE_NOSUCCEED, win);
Assertions are an integer parameter: you can combine assertions by adding them or using logical-or. The value zero is always correct. For further information, see section 9.6 .
9.2.2 Non-global target synchronization
crumb trail: > mpi-onesided > Active target synchronization: epochs > Non-global target synchronization
The `fence' mechanism (section 9.2 ) uses a global synchronization on the communicator of the window, giving a program a BSP like character. As such it is good for applications where the processes are largely synchronized, but it may lead to performance inefficiencies if processors are not in step which each other. Also, global synchronization may have hardware support, making this less restrictive than it may at first seem.
There is a mechanism that is more fine-grained, by using synchronization only on a processor group . This takes four different calls, two for starting and two for ending the epoch, separately for target and origin.
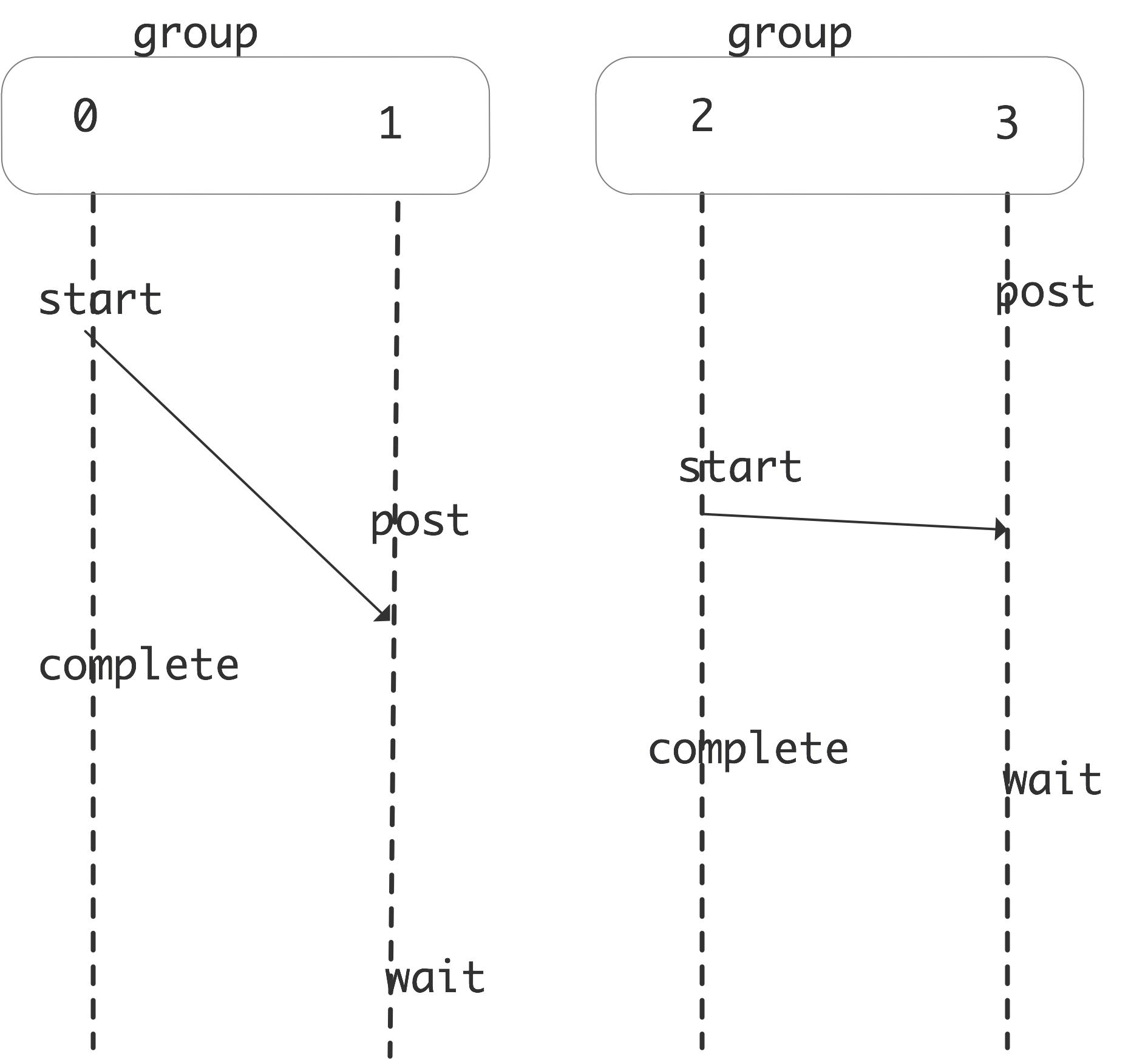
FIGURE 9.3: Window locking calls in fine-grained active target synchronization
You start and complete an exposure epoch with MPI_Win_post / MPI_Win_wait :
int MPI_Win_post(MPI_Group group, int assert, MPI_Win win) int MPI_Win_wait(MPI_Win win)In other words, this turns your window into the target for a remote access. There is a non-blocking version MPI_Win_test of MPI_Win_wait .
You start and complete an access epoch with MPI_Win_start / MPI_Win_complete :
int MPI_Win_start(MPI_Group group, int assert, MPI_Win win) int MPI_Win_complete(MPI_Win win)In other words, these calls border the access to a remote window, with the current processor being the origin of the remote access.
In the following snippet a single processor puts data on one other. Note that they both have their own definition of the group, and that the receiving process only does the post and wait calls.
// postwaitwin.c
MPI_Comm_group(comm,&all_group);
if (procno==origin) {
MPI_Group_incl(all_group,1,&target,&two_group);
// access
MPI_Win_start(two_group,0,the_window);
MPI_Put( /* data on origin: */ &my_number, 1,MPI_INT,
/* data on target: */ target,0, 1,MPI_INT,
the_window);
MPI_Win_complete(the_window);
}
if (procno==target) {
MPI_Group_incl(all_group,1,&origin,&two_group);
// exposure
MPI_Win_post(two_group,0,the_window);
MPI_Win_wait(the_window);
}
Both pairs of operations declare a group of processors ; see section 7.5.1 for how to get such a group from a communicator. On an origin processor you would specify a group that includes the targets you will interact with, on a target processor you specify a group that includes the possible origins.
9.3 Put, get, accumulate
crumb trail: > mpi-onesided > Put, get, accumulate
We will now look at the first three routines for doing one-sided operations: the Put, Get, and Accumulate call. (We will look at so-called `atomic' operations in section 9.3.7 .) These calls are somewhat similar to a Send, Receive and Reduce, except that of course only one process makes a call. Since one process does all the work, its calling sequence contains both a description of the data on the origin (the calling process) and the target (the affected other process).
As in the two-sided case, MPI_PROC_NULL can be used as a target rank.
The Accumulate routine has an MPI_Op argument that can be any of the usual operators, but no user-defined ones (see section 3.10.1 ).
9.3.1 Put
crumb trail: > mpi-onesided > Put, get, accumulate > Put
The MPI_Put call can be considered as a one-sided send. As such, it needs to specify
- the target rank
- the data to be sent from the origin, and
- the location where it is to be written on the target.
The description of the data on the origin is the usual trio of buffer/count/datatype. However, the description of the data on the target is more complicated. It has a count and a datatype, but additionally it has a displacement start of the window on the target. This displacement can be given in bytes, so its type is MPI_Aint , but strictly speaking it is a multiple of the displacement unit that was specified in the window definition.
Specifically, data is written starting at \begin{equation} \mathtt{window\_base} + \mathtt{target\_disp}\times \mathtt{disp\_unit}. \end{equation}

Here is a single put operation. Note that the window create and window fence calls are collective, so they have to be performed on all processors of the communicator that was used in the create call.
// putfence.c
MPI_Win the_window;
MPI_Win_create
(&window_data,2*sizeof(int),sizeof(int),
MPI_INFO_NULL,comm,&the_window);
MPI_Win_fence(0,the_window);
if (procno==0) {
MPI_Put
( /* data on origin: */ &my_number, 1,MPI_INT,
/* data on target: */ other,1, 1,MPI_INT,
the_window);
}
MPI_Win_fence(0,the_window);
MPI_Win_free(&the_window);
Fortran note The disp_unit variable is declared as an integer of `kind' MPI_ADDRESS_KIND :
!! putfence.F90
integer(kind=MPI_ADDRESS_KIND) :: target_displacement
target_displacement = 1
call MPI_Put( my_number, 1,MPI_INTEGER, &
other,target_displacement, &
1,MPI_INTEGER, &
the_window)
Prior to Fortran2008, specifying a literal constant, such as 0 , could lead to bizarre runtime errors; the solution was to specify a zero-valued variable of the right type. With the mpi_f08 module this is no longer allowed. Instead you get an error such as
error #6285: There is no matching specific subroutine for this generic subroutine call. [MPI_PUT]End of Fortran note
Python note MPI_Put (and Get and Accumulate) accept at minimum the origin buffer and the target rank. The displacement is by default zero.
Exercise
Revisit exercise
4.1.4.3
and solve it using
MPI_Put
.
(There is a skeleton code rightput in the repository)
End of exercise
Exercise Write code where:
- process 0 computes a random number $r$
- if $r<.5$, zero writes in the window on 1;
- if $r\geq .5$, zero writes in the window on 2.
End of exercise
9.3.2 Get
crumb trail: > mpi-onesided > Put, get, accumulate > Get
The MPI_Get call is very similar.
Example:
MPI_Win_fence(0,the_window);
if (procno==0) {
MPI_Get( /* data on origin: */ &my_number, 1,MPI_INT,
/* data on target: */ other,1, 1,MPI_INT,
the_window);
}
MPI_Win_fence(0,the_window);
## getfence.py
if procid==0 or procid==nprocs-1:
win_mem = np.empty( 1,dtype=np.float64 )
win = MPI.Win.Create( win_mem,comm=comm )
else:
win = MPI.Win.Create( None,comm=comm )
# put data on another process
win.Fence()
if procid==0 or procid==nprocs-1:
putdata = np.empty( 1,dtype=np.float64 )
putdata[0] = mydata
print("[%d] putting %e" % (procid,mydata))
win.Put( putdata,other )
win.Fence()
9.3.3 Put and get example: halo update
crumb trail: > mpi-onesided > Put, get, accumulate > Put and get example: halo update
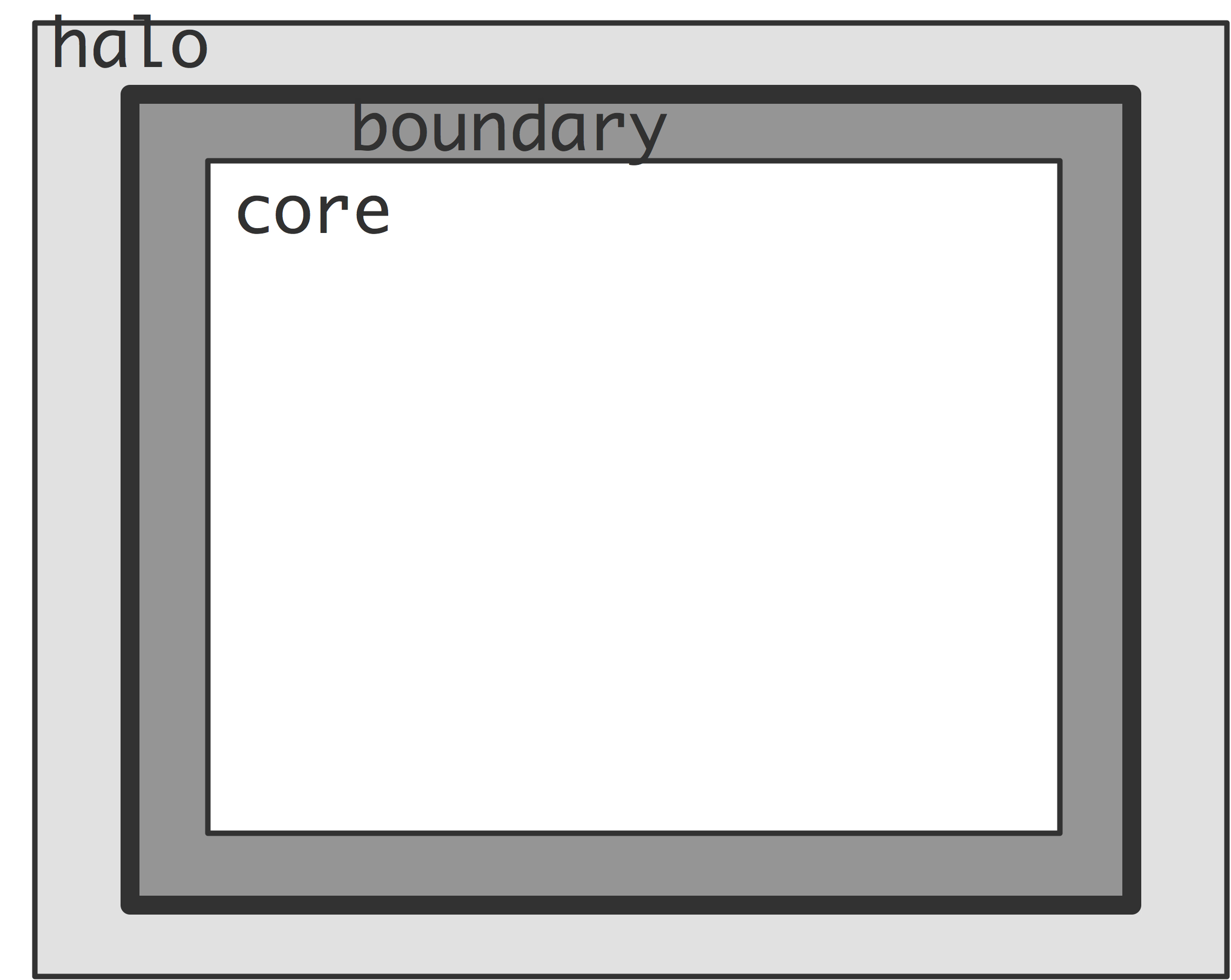
As an example, let's look at halo update . The array A is updated using the local values and the halo that comes from bordering processors, either through Put or Get operations.
In a first version we separate computation and communication. Each iteration has two fences. Between the two fences in the loop body we do the MPI_Put operation; between the second and and first one of the next iteration there is only computation, so we add the MPI_MODE_NOPRECEDE and MPI_MODE_NOSUCCEED assertions. The MPI_MODE_NOSTORE assertion states that the local window was not updated: the Put operation only works on remote windows.
for ( .... ) {
update(A);
MPI_Win_fence(MPI_MODE_NOPRECEDE, win);
for(i=0; i < toneighbors; i++)
MPI_Put( ... );
MPI_Win_fence((MPI_MODE_NOSTORE | MPI_MODE_NOSUCCEED), win);
}
For much more about
assertions, see section
9.6
below.
Next, we split the update in the core part, which can be done purely from local values, and the boundary, which needs local and halo values. Update of the core can overlap the communication of the halo.
for ( .... ) {
update_boundary(A);
MPI_Win_fence((MPI_MODE_NOPUT | MPI_MODE_NOPRECEDE), win);
for(i=0; i < fromneighbors; i++)
MPI_Get( ... );
update_core(A);
MPI_Win_fence(MPI_MODE_NOSUCCEED, win);
}
The
MPI_MODE_NOPRECEDE
and
MPI_MODE_NOSUCCEED
assertions still hold, but the
Get
operation implies that instead of
MPI_MODE_NOSTORE
in the
second fence, we use
MPI_MODE_NOPUT
in the first.
9.3.4 Accumulate
crumb trail: > mpi-onesided > Put, get, accumulate > Accumulate
A third one-sided routine is MPI_Accumulate which does a reduction operation on the results that are being put.
Accumulate is an atomic reduction with remote result. This means that multiple accumulates to a single target in the same epoch give the correct result. As with MPI_Reduce , the order in which the operands are accumulated is undefined.
The same predefined operators are available, but no user-defined ones. There is one extra operator: MPI_REPLACE , this has the effect that only the last result to arrive is retained.
Exercise
Implement an `all-gather' operation using one-sided communication:
each processor stores a single number, and you want each processor
to build up an array that contains the values from all
processors. Note that you do not need a special case for a processor
collecting its own value: doing `communication' between a processor
and itself is perfectly legal.
End of exercise
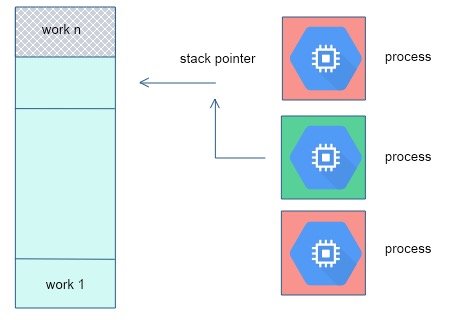
FIGURE 9.4: Pool of work descriptors with shared stack pointers
For the next exercise, refer to figure 9.4 .
Exercise
Implement a shared counter:
- One process maintains a counter;
- Iterate: all others at random moments update this counter.
- When the counter is no longer positive, everyone stops iterating.
End of exercise
9.3.5 Ordering and coherence of RMA operations
crumb trail: > mpi-onesided > Put, get, accumulate > Ordering and coherence of RMA operations
There are few guarantees about what happens inside one epoch.
- No ordering of Get and Put/Accumulate operations: if you do both, there is no guarantee whether the Get will find the value before or after the update.
- No ordering of multiple Puts. It is safer to do an Accumulate.
- Instead of multiple Put operations, use Accumulate with MPI_REPLACE .
- MPI_Get_accumulate with MPI_NO_OP is safe.
- Multiple Accumulate operations from one origin are done in program order by default. To allow reordering, for instance to have all reads happen after all writes, use the info parameter when the window is created; section 9.5.3 .
9.3.6 Request-based operations
crumb trail: > mpi-onesided > Put, get, accumulate > Request-based operations
Analogous to MPI_Isend there are request-based one-sided operations: MPI_Rput and similarly MPI_Rget and MPI_Raccumulate and MPI_Rget_accumulate . These only apply to passive target synchronization. Any MPI_Win_flush... call also terminates these transfers.
9.3.7 Atomic operations
crumb trail: > mpi-onesided > Put, get, accumulate > Atomic operations
One-sided calls are said to emulate shared memory in MPI, but the put and get calls are not enough for certain scenarios with shared data. Consider the scenario where:
- One process stores a table of work descriptors, and a pointer to the first unprocessed descriptor;
- Each process reads the pointer, reads the corresponding descriptor, and increments the pointer; and
- A process that has read a descriptor then executes the corresponding task.
The problem is that reading and updating the pointer is not an atomic operation it is possible that multiple processes get hold of the same value; conversely, multiple updates of the pointer may lead to work descriptors being skipped. These different overall behaviors, depending on precise timing of lower level events, are called a race condition .
In MPI-3 some atomic routines have been added. Both MPI_Fetch_and_op and MPI_Get_accumulate atomically retrieve data from the window indicated, and apply an operator, combining the data on the target with the data on the origin. Unlike Put and Get, it is safe to have multiple atomic operations in the same epoch.
Both routines perform the same operations: return data before the operation, then atomically update data on the target, but MPI_Get_accumulate is more flexible in data type handling. The more simple routine, MPI_Fetch_and_op , which operates on only a single element, allows for faster implementations, in particular through hardware support.
Use of MPI_NO_OP as the MPI_Op turns these routines into an atomic Get. Similarly, using MPI_REPLACE turns them into an atomic Put.
Exercise Redo exercise 9.4 using MPI_Fetch_and_op . The problem is again to make sure all processes have the same view of the shared counter.
Does it work to make the fetch-and-op conditional? Is there a way to
do it unconditionally? What should the `break' test be, seeing that
multiple processes can update the counter at the same time?
End of exercise
Example A root process has a table of data; the other processes do atomic gets and update of that data using passive target synchronization through MPI_Win_lock .
// passive.cxx
if (procno==repository) {
// Repository processor creates a table of inputs
// and associates that with the window
}
if (procno!=repository) {
float contribution=(float)procno,table_element;
int loc=0;
MPI_Win_lock(MPI_LOCK_EXCLUSIVE,repository,0,the_window);
// read the table element by getting the result from adding zero
MPI_Fetch_and_op
(&contribution,&table_element,MPI_FLOAT,
repository,loc,MPI_SUM,the_window);
MPI_Win_unlock(repository,the_window);
}
## passive.py
if procid==repository:
# repository process creates a table of inputs
# and associates it with the window
win_mem = np.empty( ninputs,dtype=np.float32 )
win = MPI.Win.Create( win_mem,comm=comm )
else:
# everyone else has an empty window
win = MPI.Win.Create( None,comm=comm )
if procid!=repository:
contribution = np.empty( 1,dtype=np.float32 )
contribution[0] = 1.*procid
table_element = np.empty( 1,dtype=np.float32 )
win.Lock( repository,lock_type=MPI.LOCK_EXCLUSIVE )
win.Fetch_and_op( contribution,table_element,repository,0,MPI.SUM)
win.Unlock( repository )
End of example
Finally, MPI_Compare_and_swap swaps the origin and target data if the target data equals some comparison value.
9.3.7.1 A case study in atomic operations
crumb trail: > mpi-onesided > Put, get, accumulate > Atomic operations > A case study in atomic operations
Let us consider an example where a process, identified by counter_process , has a table of work descriptors, and all processes, including the counter process, take items from it to work on. To avoid duplicate work, the counter process has as counter that indicates the highest numbered available item. The part of this application that we simulate is this:
- a process reads the counter, to find an available work item; and
- subsequently decrements the counter by one.
We initialize the window content, under the separate memory model:
// countdownop.c
MPI_Win_fence(0,the_window);
if (procno==counter_process)
MPI_Put(&counter_init,1,MPI_INT,
counter_process,0,1,MPI_INT,
the_window);
MPI_Win_fence(0,the_window);
We start by considering the naive approach, where we execute the above scheme literally with MPI_Get and MPI_Put :
// countdownput.c
MPI_Win_fence(0,the_window);
int counter_value;
MPI_Get( &counter_value,1,MPI_INT,
counter_process,0,1,MPI_INT,
the_window);
MPI_Win_fence(0,the_window);
if (i_am_available) {
int decrement = -1;
counter_value += decrement;
MPI_Put
( &counter_value, 1,MPI_INT,
counter_process,0,1,MPI_INT,
the_window);
}
MPI_Win_fence(0,the_window);
This scheme is correct if only process has a true value for i_am_available : that processes `owns' the current counter values, and it correctly updates the counter through the MPI_Put operation. However, if more than one process is available, they get duplicate counter values, and the update is also incorrect. If we run this program, we see that the counter did not get decremented by the total number of `put' calls.
Exercise
Supposing only one process is available, what is the function
of the middle of the three fences? Can it be omitted?
End of exercise
We can fix the decrement of the counter by using MPI_Accumulate for the counter update, since it is atomic: multiple updates in the same epoch all get processed.
// countdownacc.c
MPI_Win_fence(0,the_window);
int counter_value;
MPI_Get( &counter_value,1,MPI_INT,
counter_process,0,1,MPI_INT,
the_window);
MPI_Win_fence(0,the_window);
if (i_am_available) {
int decrement = -1;
MPI_Accumulate
( &decrement, 1,MPI_INT,
counter_process,0,1,MPI_INT,
MPI_SUM,
the_window);
}
MPI_Win_fence(0,the_window);
This scheme still suffers from the problem that processes will obtain duplicate counter values. The true solution is to combine the `get' and `put' operations into one atomic action; in this case MPI_Fetch_and_op :
MPI_Win_fence(0,the_window);
int
counter_value;
if (i_am_available) {
int
decrement = -1;
total_decrement++;
MPI_Fetch_and_op
( /* operate with data from origin: */ &decrement,
/* retrieve data from target: */ &counter_value,
MPI_INT, counter_process, 0, MPI_SUM,
the_window);
}
MPI_Win_fence(0,the_window);
if (i_am_available) {
my_counter_values[n_my_counter_values++] = counter_value;
}
Now, if there are multiple accesses, each retrieves the counter value and updates it in one atomic, that is, indivisible, action.
9.4 Passive target synchronization
crumb trail: > mpi-onesided > Passive target synchronization
In passive target synchronization only the origin is actively involved: the target makes no synchronization calls. This means that the origin process remotely locks the window on the target, performs a one-sided transfer, and releases the window by unlocking it again.
During an access epoch, also called an passive target epoch in this case (the concept of `exposure epoch' makes no sense with passive target synchronization), a process can initiate and finish a one-sided transfer. Typically it will lock the window with MPI_Win_lock :
if (rank == 0) {
MPI_Win_lock (MPI_LOCK_EXCLUSIVE, 1, 0, win);
MPI_Put (outbuf, n, MPI_INT, 1, 0, n, MPI_INT, win);
MPI_Win_unlock (1, win);
}
Remark
The possibility to lock a window is not guaranteed for windows
that are not created (possibly internally) by
MPI_Alloc_mem
,
that is, all but
MPI_Win_create
.
End of remark
9.4.1 Lock types
crumb trail: > mpi-onesided > Passive target synchronization > Lock types
A lock is needed to start an access epoch , that is, for an origin to acquire the capability to access a target. You can either acquire a lock on a specific process with MPI_Win_lock , or on all processes (in a communicator) with MPI_Win_lock_all . Unlike MPI_Win_fence , this is not a collective call. Also, it is possible to have multiple access epochs through MPI_Win_lock active simultaenously.
The two lock types are:
- MPI_LOCK_SHARED : multiple processes can access the window on the same rank. If multiple processes perform a MPI_Get call there is no problem; with MPI_Put and similar calls there is a consistency problem; see below.
- MPI_LOCK_EXCLUSIVE : an origin gets exclusive access to the window on a certain target. Unlike the shared lock, this has no consistency problems.
You can only specify a lock type in MPI_Win_lock ; MPI_Win_lock_all is always shared.
To unlock a window, use MPI_Win_unlock , % includes unlock_all respectively MPI_Win_unlock_all .
Exercise Investigate atomic updates using passive target synchronization. Use MPI_Win_lock with an exclusive lock, which means that each process only acquires the lock when it absolutely has to.
-
All processs but one update a window:
int one=1; MPI_Fetch_and_op(&one, &readout, MPI_INT, repo, zero_disp, MPI_SUM, the_win); - while the remaining process spins until the others have performed their update.
Can you replace the exclusive lock with a shared one? (There is a skeleton code lockfetch in the repository)
End of exercise
Exercise As exercise 9.4.1 , but now use a shared lock: all processes acquire the lock simultaneously and keep it as long as is needed.
The problem here is that coherence between window buffers and local variables is
now not forced by a fence or releasing a lock. Use
MPI_Win_flush_local
to
force coherence of a window (on another process) and the local variable from
MPI_Fetch_and_op
.
(There is a skeleton code lockfetchshared in the repository)
End of exercise
9.4.2 Lock all
crumb trail: > mpi-onesided > Passive target synchronization > Lock all
To lock the windows of all processes in the group of the windows, use MPI_Win_lock_all . This is not a collective call: the `all' part refers to the fact that one process is locking the window on all processes.
- The assertion value can be zero, or MPI_MODE_NOCHECK , which asserts that no other process will acquire a competing lock.
- There is no `locktype' parameter: this is a shared lock.
The corresponding unlock is MPI_Win_unlock_all .
The expected use of a `lock/unlock all' is that they surround an extended epoch with get/put and flush calls.
9.4.3 Completion and consistency in passive target synchronization
crumb trail: > mpi-onesided > Passive target synchronization > Completion and consistency in passive target synchronization
In one-sided transfer one should keep straight the multiple instances of the data, and the various completion s that effect their consistency .
- The user data. This is the buffer that is passed to an RMA call. For instance, after an MPI_Put call, but still in an access epoch, the user buffer is not safe to reuse. Making sure the buffer has been transferred is called local completion .
- The window data. While this may be publicly accessible, it is not necessarily always consistent with internal copies.
- The remote data. Even a successful MPI_Put does not guarantee that the other process has received the data. A successful transfer is a remote completion .
As observed, RMA operations are nonblocking, so we need mechanisms to ensure that an operation is completed, and to ensure consistency of the user and window data.
Completion of the RMA operations in a passive target epoch is ensured with MPI_Win_unlock or MPI_Win_unlock_all , similar to the use of MPI_Win_fence in active target synchronization.
If the passive target epoch is of greater duration, and no unlock operation is used to ensure completion, the following calls are available.
Remark Using flush routines with active target synchronization (or generally outside a passive target epoch) you are likely to get a message
Wrong synchronization of RMA calls
End of remark
9.4.3.1 Local completion
crumb trail: > mpi-onesided > Passive target synchronization > Completion and consistency in passive target synchronization > Local completion
The call MPI_Win_flush_local ensure that all operations with a given target is completed at the origin. For instance, for calls to MPI_Get or MPI_Fetch_and_op the local result is available after the MPI_Win_flush_local .
With MPI_Win_flush_local_all local operations are concluded for all targets. This will typically be used with MPI_Win_lock_all (section 9.4.2 ).
9.4.3.2 Remote completion
crumb trail: > mpi-onesided > Passive target synchronization > Completion and consistency in passive target synchronization > Remote completion
The calls MPI_Win_flush and MPI_Win_flush_all effect completion of all outstanding RMA operations on the target, so that other processes can access its data. This is useful for MPI_Put operations, but can also be used for atomic operations such as MPI_Fetch_and_op .
9.4.3.3 Window synchronization
crumb trail: > mpi-onesided > Passive target synchronization > Completion and consistency in passive target synchronization > Window synchronization
Under the separate memory model the user code can hold a buffer that is not coherent with the internal window data. The call MPI_Win_sync synchronizes private and public copies of the window.
9.5 More about window memory
crumb trail: > mpi-onesided > More about window memory
9.5.1 Memory models
crumb trail: > mpi-onesided > More about window memory > Memory models
You may think that the window memory is the same as the buffer you pass to MPI_Win_create or that you get from MPI_Win_allocate (section 9.1.1 ). This is not necessarily true, and the actual state of affairs is called the memory model . There are two memory models:
- Under the unified memory model, the buffer in process space is indeed the window memory, or at least they are kept coherent . This means that after completion of an epoch you can read the window contents from the buffer. To get this, the window needs to be created with MPI_Win_allocate_shared . This memory model is required for MPI shared memory; chapter MPI topic: Shared memory .
- Under the separate memory model, the buffer in process space is the private window and the target of put/get operations is the public window and the two are not the same and are not kept coherent. Under this model, you need to do an explicit get to read the window contents.
You can query the model of a window using the MPI_Win_get_attr call with the MPI_WIN_MODEL keyword:
// window.c
int *modelstar,flag;
MPI_Win_get_attr(the_window,MPI_WIN_MODEL,&modelstar,&flag);
int model = *modelstar;
if (procno==0)
printf("Window model is unified: %d\n",model==MPI_WIN_UNIFIED);
- MPI_WIN_SEPARATE ,
- MPI_WIN_UNIFIED ,
9.5.2 Dynamically attached memory
crumb trail: > mpi-onesided > More about window memory > Dynamically attached memory
In section 9.1.1 we looked at simple ways to create a window and its memory.
It is also possible to have windows where the size is dynamically set. Create a dynamic window with MPI_Win_create_dynamic and attach memory to the window with MPI_Win_attach .
At first sight, the code looks like splitting up a MPI_Win_create call into separate creation of the window and declaration of the buffer:
// windynamic.c MPI_Win_create_dynamic(MPI_INFO_NULL,comm,&the_window); if (procno==data_proc) window_buffer = (int*) malloc( 2*sizeof(int) ); MPI_Win_attach(the_window,window_buffer,2*sizeof(int));
However, there is an important difference in how the window is addressed in RMA operations. With all other window models, the displacement parameter is measured relative in units from the start of the buffer, here the displacement is an absolute address. This means that we need to get the address of the window buffer with MPI_Get_address and communicate it to the other processes:
MPI_Aint data_address;
if (procno==data_proc) {
MPI_Get_address(window_buffer,&data_address);
}
MPI_Bcast(&data_address,1,MPI_AINT,data_proc,comm);
Location of the data, that is, the displacement parameter, is then given as an absolute location of the start of the buffer plus a count in bytes; in other words, the displacement unit is 1. In this example we use MPI_Get to find the second integer in a window buffer:
MPI_Aint disp = data_address+1*sizeof(int); MPI_Get( /* data on origin: */ retrieve, 1,MPI_INT, /* data on target: */ data_proc,disp, 1,MPI_INT, the_window);
Notes.
- The attached memory can be released with MPI_Win_detach .
- The above fragments show that an origin process has the actual address of the window buffer. It is an error to use this if the buffer is not attached to a window.
- In particular, one has to make sure that the attach call is concluded before performing RMA operations on the window.
9.5.3 Window usage hints
crumb trail: > mpi-onesided > More about window memory > Window usage hints
The following keys can be passed as info argument:
- no_locks : if set to true, passive target synchronization (section 9.4 ) will not be used on this window.
- accumulate_ordering : a comma-separated list of the keywords rar , raw , war , waw can be specified. This indicates that reads or writes from MPI_Accumulate or MPI_Get_accumulate can be reordered, subject to certain constraints.
- accumulate_ops : the value same_op indicates that concurrent Accumulate calls use the same operator; same_op_no_op indicates the same operator or MPI_NO_OP .
9.5.4 Window information
crumb trail: > mpi-onesided > More about window memory > Window information
The MPI_Info parameter (see section 15.1.1 for info objects) can be used to pass implementation-dependent information.
A number of attributes are stored with a window when it is created.
-
MPI_WIN_BASE
for
obtaining a pointer to the start of the window area:
void *base; MPI_Win_get_attr(win, MPI_WIN_BASE, &base, &flag)
-
MPI_WIN_SIZE
and
MPI_WIN_DISP_UNIT
for
obtaining the size and
window displacement unit
:
MPI_Aint *size; MPI_Win_get_attr(win, MPI_WIN_SIZE, &size, &flag), int *disp_unit; MPI_Win_get_attr(win, MPI_WIN_DISP_UNIT, &disp_unit, &flag),
-
MPI_WIN_CREATE_FLAVOR
for determining
the type of create call used:
int *create_kind; MPI_Win_get_attr(win, MPI_WIN_CREATE_FLAVOR, &create_kind, &flag)
with possible values:- MPI_WIN_FLAVOR_CREATE if the window was create with MPI_Win_create ;
- MPI_WIN_FLAVOR_ALLOCATE if the window was create with MPI_Win_allocate ;
- MPI_WIN_FLAVOR_DYNAMIC if the window was create with MPI_Win_create_dynamic . In this case the base is MPI_BOTTOM and the size is zero;
- MPI_WIN_FLAVOR_SHARED if the window was create with MPI_Win_allocate_shared ;
- MPI_WIN_MODEL for querying the window memory model; see section 9.5.1 .
Get the group of processes (see section 7.5 ) associated with a window:
int MPI_Win_get_group(MPI_Win win, MPI_Group *group)
Window information objects (see section 15.1.1 ) can be set and retrieved:
int MPI_Win_set_info(MPI_Win win, MPI_Info info)
int MPI_Win_get_info(MPI_Win win, MPI_Info *info_used)
9.6 Assertions
crumb trail: > mpi-onesided > Assertions
The routines
- (Active target synchronization) MPI_Win_fence , MPI_Win_post , MPI_Win_start ;
- (Passive target synchronization) MPI_Win_lock , MPI_Win_lockall ,
-
MPI_Win_start
Supports the option:
- MPI_MODE_NOCHECK the matching calls to MPI_Win_post have already completed on all target processes when the call to MPI_Win_start is made. The nocheck option can be specified in a start call if and only if it is specified in each matching post call. This is similar to the optimization of ``ready-send'' that may save a handshake when the handshake is implicit in the code. (However, ready-send is matched by a regular receive, whereas both start and post must specify the nocheck option.)
-
MPI_Win_post
supports the following options:
- MPI_MODE_NOCHECK the matching calls to MPI_Win_start have not yet occurred on any origin processes when the call to MPI_Win_post is made. The nocheck option can be specified by a post call if and only if it is specified by each matching start call.
- MPI_MODE_NOSTORE the local window was not updated by local stores (or local get or receive calls) since last synchronization. This may avoid the need for cache synchronization at the post call.
- MPI_MODE_NOPUT the local window will not be updated by put or accumulate calls after the post call, until the ensuing (wait) synchronization. This may avoid the need for cache synchronization at the wait call.
-
MPI_Win_fence
supports the following options:
- MPI_MODE_NOSTORE the local window was not updated by local stores (or local get or receive calls) since last synchronization.
- MPI_MODE_NOPUT the local window will not be updated by put or accumulate calls after the fence call, until the ensuing (fence) synchronization.
- MPI_MODE_NOPRECEDE the fence does not complete any sequence of locally issued RMA calls. If this assertion is given by any process in the window group, then it must be given by all processes in the group.
- MPI_MODE_NOSUCCEED the fence does not start any sequence of locally issued RMA calls. If the assertion is given by any process in the window group, then it must be given by all processes in the group.
-
MPI_Win_lock
and
MPI_Win_lock_all
support the following option:
- MPI_MODE_NOCHECK no other process holds, or will attempt to acquire a conflicting lock, while the caller holds the window lock. This is useful when mutual exclusion is achieved by other means, but the coherence operations that may be attached to the lock and unlock calls are still required.
9.7 Implementation
crumb trail: > mpi-onesided > Implementation
You may wonder how one-sided communication is realized\footnote{For more on this subject, see [thakur:ijhpca-sync] .}. Can a processor somehow get at another processor's data? Unfortunately, no.
Active target synchronization is implemented in terms of two-sided communication. Imagine that the first fence operation does nothing, unless it concludes prior one-sided operations. The Put and Get calls do nothing involving communication, except for marking with what processors they exchange data. The concluding fence is where everything happens: first a global operation determines which targets need to issue send or receive calls, then the actual sends and receive are executed.
Exercise
Assume that only Get operations are performed during an epoch.
Sketch how these are translated to send/receive pairs.
The problem here is how the senders find out that they need to send.
Show that you can solve this with an
MPI_Reduce_scatter
call.
End of exercise
The previous paragraph noted that a collective operation was necessary to determine the two-sided traffic. Since collective operations induce some amount of synchronization, you may want to limit this.
Exercise
Argue that the mechanism with window post/wait/start/complete operations
still needs a collective, but that this is less burdensome.
End of exercise
Passive target synchronization needs another mechanism entirely. Here the target process needs to have a background task (process, thread, daemon,\ldots) running that listens for requests to lock the window. This can potentially be expensive.
\newpage
9.8 Review questions
crumb trail: > mpi-onesided > Review questionsFind all the errors in this code.
#include <mpi.h>
#include <stdio.h>
#include <stdlib.h>
#define MASTER 0
int main(int argc, char *argv[])
{
MPI_Init(&argc, &argv);
MPI_Comm comm = MPI_COMM_WORLD;
int r, p;
MPI_Comm_rank(comm, &r);
MPI_Comm_size(comm, &p);
printf("Hello from %d\n", r);
int result[1] = {0};
//int assert = MPI_MODE_NOCHECK;
int assert = 0;
int one = 1;
MPI_Win win_res;
MPI_Win_allocate(1 * sizeof(MPI_INT), sizeof(MPI_INT), MPI_INFO_NULL, comm, &result[0], &win_res);
MPI_Win_lock_all(assert, win_res);
if (r == MASTER) {
result[0] = 0;
do{
MPI_Fetch_and_op(&result, &result , MPI_INT, r, 0, MPI_NO_OP, win_res);
printf("result: %d\n", result[0]);
} while(result[0] != 4);
printf("Master is done!\n");
} else {
MPI_Fetch_and_op(&one, &result, MPI_INT, 0, 0, MPI_SUM, win_res);
}
MPI_Win_unlock_all(win_res);
MPI_Win_free(&win_res);
MPI_Finalize();
return 0;