Getting started with MPI
Experimental html version of Parallel Programming in MPI, OpenMP, and PETSc by Victor Eijkhout. download the textbook at https:/theartofhpc.com/pcse
1.2 : History
1.3 : Basic model
1.4 : Making and running an MPI program
1.5 : Language bindings
1.5.1 : C
1.5.2 : C++, including MPL
1.5.3 : Fortran
1.5.4 : Python
1.5.5 : How to read routine signatures
1.5.5.1 : C
1.5.5.2 : Fortran
1.5.5.3 : Python
1.6 : Review
Back to Table of Contents
1 Getting started with MPI
In this chapter you will learn the use of the main tool for distributed memory programming: the MPI library. The MPI library has about 250 routines, many of which you may never need. Since this is a textbook, not a reference manual, we will focus on the important concepts and give the important routines for each concept. What you learn here should be enough for most common purposes. You are advised to keep a reference document handy, in case there is a specialized routine, or to look up subtleties about the routines you use.
1.1 Distributed memory and message passing
crumb trail: > mpi-started > Distributed memory and message passing
In its simplest form, a distributed memory machine is a collection of single computers hooked up with network cables. In fact, this has a name: a Beowulf cluster . As you recognize from that setup, each processor can run an independent program, and has its own memory without direct access to other processors' memory. MPI is the magic that makes multiple instantiations of the same executable run so that they know about each other and can exchange data through the network.
One of the reasons that MPI is so successful as a tool for high performance on clusters is that it is very explicit: the programmer controls many details of the data motion between the processors. Consequently, a capable programmer can write very efficient code with MPI. Unfortunately, that programmer will have to spell things out in considerable detail. For this reason, people sometimes call MPI `the assembly language of parallel programming'. If that sounds scary, be assured that things are not that bad. You can get started fairly quickly with MPI, using just the basics, and coming to the more sophisticated tools only when necessary.
Another reason that MPI was a big hit with programmers is that it does not ask you to learn a new language: it is a library that can be interfaced to C/C++ or Fortran; there are even bindings to Python and Java (not described in this course). This does not mean, however, that it is simple to `add parallelism' to an existing sequential program. An MPI version of a serial program takes considerable rewriting; certainly more than shared memory parallelism through OpenMP, discussed later in this book.
MPI is also easy to install: there are free implementations that you can download and install on any computer that has a Unix-like operating system, even if that is not a parallel machine. However, if you are working on a supercomputer cluster, likely there will already be an MPI installation, tuned to that machine's network.
1.2 History
crumb trail: > mpi-started > History
Before the MPI standard was developed in 1993-4, there were many libraries for distributed memory computing, often proprietary to a vendor platform. MPI standardized the inter-process communication mechanisms. Other features, such as process management in PVM , or parallel I/O were omitted. Later versions of the standard have included many of these features.
Since MPI was designed by a large number of academic and commercial participants, it quickly became a standard. A few packages from the pre-MPI era, such as Charmpp [charmpp] , are still in use since they support mechanisms that do not exist in MPI.
1.3 Basic model
crumb trail: > mpi-started > Basic model
Here we sketch the two most common scenarios for using MPI. In the first, the user is working on an interactive machine, which has network access to a number of hosts, typically a network of workstations; see figure 1.1 .
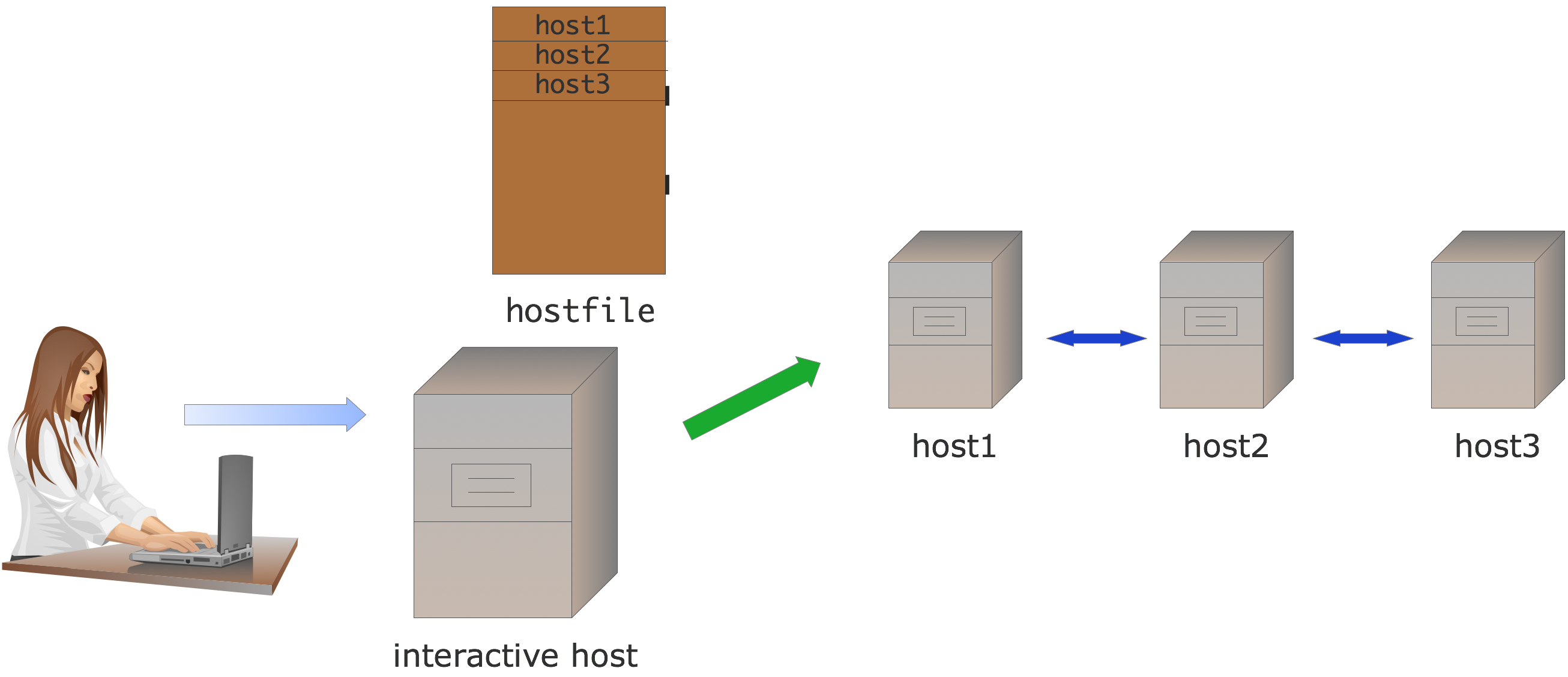
FIGURE 1.1: Interactive MPI setup
The user types the command mpiexec \footnote {A command variant is mpirun ; your local cluster may have a different mechanism.} and supplies
- The number of hosts involved,
- their names, possibly in a hostfile,
- and other parameters, such as whether to include the interactive host; followed by
- the name of the program and its parameters.
In the second scenario (figure 1.2 ) the user prepares a batch job script with commands, and these will be run when the batch scheduler gives a number of hosts to the job.
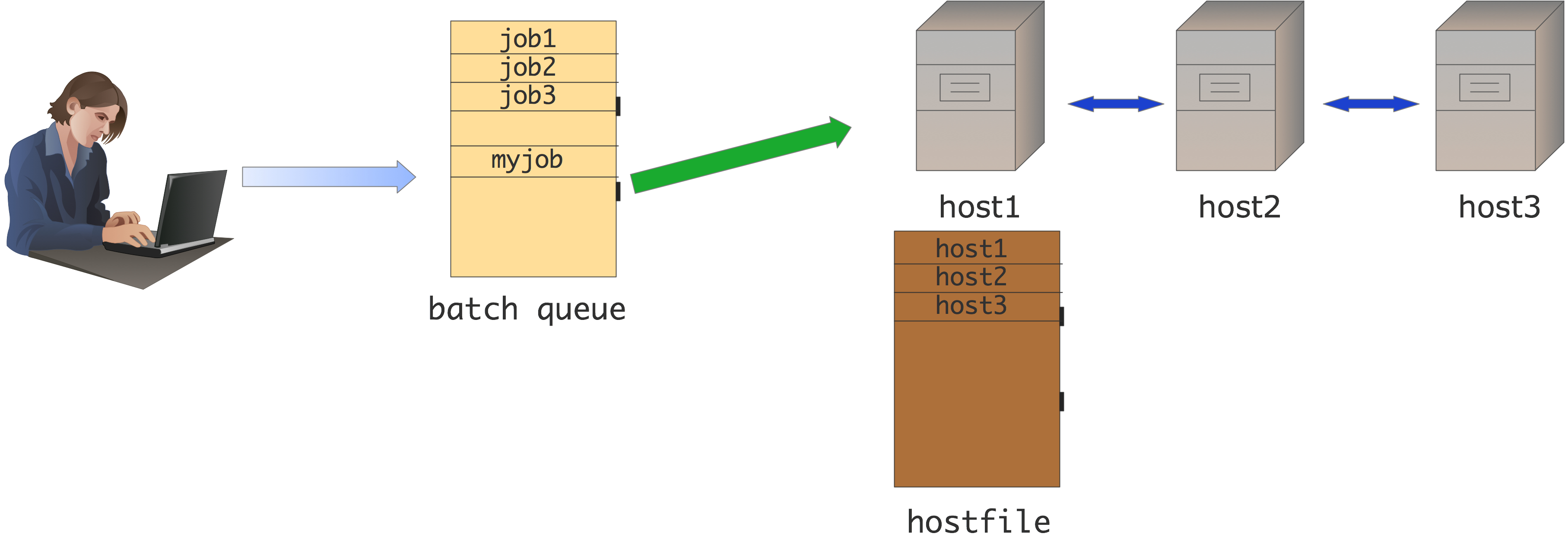
FIGURE 1.2: Batch MPI setup
Now the batch script contains the mpiexec command% \begin{istc} , or some variant such as ibrun \end{istc} , and the hostfile is dynamically generated when the job starts. Since the job now runs at a time when the user may not be logged in, any screen output goes into an output file.
You see that in both scenarios the parallel program is started by the mpiexec command using an SPMD mode of execution: all hosts execute the same program. It is possible for different hosts to execute different programs, but we will not consider that in this book.
There can be options and environment variables that are specific to some MPI installations, or to the network.
-
mpich
and its derivatives such as
Intel MPI
or
Cray MPI
have
mpiexec options
:
https://www.mpich.org/static/docs/v3.1/www1/mpiexec.html
1.4 Making and running an MPI program
crumb trail: > mpi-started > Making and running an MPI program
MPI is a library, called from programs in ordinary programming languages such as C/C++ or Fortran. To compile such a program you use your regular compiler:
gcc -c my_mpi_prog.c -I/path/to/mpi.h gcc -o my_mpi_prog my_mpi_prog.o -L/path/to/mpi -lmpichHowever, MPI libraries may have different names between different architectures, making it hard to have a portable makefile. Therefore, MPI typically has shell scripts around your compiler call, called mpicc , mpicxx , mpif90 for C/C++/Fortran respectively.
mpicc -c my_mpi_prog.c mpicc -o my_mpi_prog my_mpi_prog.o
If you want to know what \indextermttdef{mpicc} does, there is usually an option that prints out its definition. On a Mac with the clang compiler:
$$ mpicc -show clang -fPIC -fstack-protector -fno-stack-check -Qunused-arguments -g3 -O0 -Wno-implicit-function-declaration -Wl,-flat_namespace -Wl,-commons,use_dylibs -I/Users/eijkhout/Installation/petsc/petsc-3.16.1/macx-clang-debug/include -L/Users/eijkhout/Installation/petsc/petsc-3.16.1/macx-clang-debug/lib -lmpi -lpmpi
Remark
In
OpenMPI
, these commands are
binary executables by default,
but you can make it a shell script by passing the
--enable-script-wrapper-compilers
option at configure time.
End of remark
MPI programs can be run on many different architectures. Obviously it is your ambition (or at least your dream) to run your code on a cluster with a hundred thousand processors and a fast network. But maybe you only have a small cluster with plain ethernet . Or maybe you're sitting in a plane, with just your laptop. An MPI program can be run in all these circumstances -- within the limits of your available memory of course.
The way this works is that you do not start your executable directly, but you use a program, typically called mpiexec or something similar, which makes a connection to all available processors and starts a run of your executable there. So if you have a thousand nodes in your cluster, mpiexec can start your program once on each, and if you only have your laptop it can start a few instances there. In the latter case you will of course not get great performance, but at least you can test your code for correctness.
1.5 Language bindings
crumb trail: > mpi-started > Language bindings
1.5.1 C
crumb trail: > mpi-started > Language bindings > C
The MPI library is written in C. However, the standard is careful to distinguish between MPI routines, versus their C bindings . In fact, as of MPI MPI-4, for a number of routines there are two bindings, depending on whether you want 4 byte integers, or larger. See section 6.4 , in particular 6.4.1 .
1.5.2 C++, including MPL
crumb trail: > mpi-started > Language bindings > C++, including MPL
C++ bindings but they were declared deprecated, and have been officially removed in the \mpistandardsub{3}{C++ bindings removed} standard. Thus, MPI can be used from C++ by including
#include <mpi.h>and using the C API.
The boost library has its own version of MPI, but it seems not to be under further development. A recent effort at idiomatic C++ support is MPL
https://github.com/rabauke/mpl . This book has an index of MPL notes and commands: section sec:idx:mpl .
MPL note MPL is a C++ header-only library. Notes on MPI usage from MPL will be indicated like this. End of MPL note
1.5.3 Fortran
crumb trail: > mpi-started > Language bindings > Fortran
Fortran note Fortran-specific notes will be indicated with a note like this. End of Fortran note
Traditionally, Fortran bindings for MPI look very much like the C ones, except that each routine has a final error return parameter. You will find that a lot of MPI code in Fortran conforms to this.
However, in the MPI 3 % standard it is recommended that an MPI implementation providing a Fortran interface provide a module named \indextermttdef{mpi_f08} that can be used in a Fortran program. This incorporates the following improvements:
- This defines MPI routines to have an optional final parameter for the error.
- There are some visible implications of using the mpi_f08 module, mostly related to the fact that some of the `MPI datatypes' such as MPI_Comm , which were declared as Integer previously, are now a Fortran Type . See the following sections for details: Communicator 7.1 , Datatype 6.1 , Info 15.1.1 , Op 3.10.2 , Request 4.2.1 , Status 4.3 , Window 9.1 .
-
The
mpi_f08
module solves a problem with previous
Fortran90 bindings
:
Fortran90 is a strongly typed language, so it is not possible to pass
argument by reference to their address, as C/C++ do with the
void*
type for send and receive buffers. This was solved by having
separate routines for each datatype, and providing an
Interface
block
in the MPI module. If you manage to request a version that does not exist,
the compiler will display a message like
There is no matching specific subroutine for this generic subroutine call [MPI_Send]
For details seehttp://mpi-forum.org/docs/mpi-3.1/mpi31-report/node409.htm .
1.5.4 Python
crumb trail: > mpi-started > Language bindings > Python
Python note Python-specific notes will be indicated with a note like this.
The \indextermttdef{mpi4py} package [Dalcin:m4py12,mpi4py:homepage] of python bindings is not defined by the MPI standards committee. Instead, it is the work of an individual, Lisandro Dalcin .
In a way, the Python interface is the most elegant. It uses OO techniques such as methods on objects, and many default arguments.
Notable about the Python bindings is that many communication routines exist in two variants:
- a version that can send arbitrary Python objects. These routines have lowercase names such as bcast ; and
- a version that sends numpy objects; these routines have names such as Bcast . Their syntax can be slightly different.
Codes with mpi4py can be interfaced to other languages through Swig or conversion routines.
Data in numpy can be specified as a simple object, or [data, (count,displ), datatype] .
1.5.5 How to read routine signatures
crumb trail: > mpi-started > Language bindings > How to read routine signatures
Throughout the MPI part of this book we will give the reference syntax of the routines. This typically comprises:
- The semantics: routine name and list of parameters and what they mean.
- C synxtax: the routine definition as it appears in the mpi.h file.
- Fortran syntax: routine definition with parameters, giving in/out specification.
- Python syntax: routine name, indicating to what class it applies, and parameter, indicating which ones are optional.
These `routine signatures' look like code but they are not! Here is how you translate them.
1.5.5.1 C
crumb trail: > mpi-started > Language bindings > How to read routine signatures > C
The typically C routine specification in MPI looks like:
int MPI_Comm_size(MPI_Comm comm,int *nprocs)This means that
-
The routine returns an
int
parameter. Strictly speaking you
should test against
MPI_SUCCESS
(for all error codes,
see section
15.2.1
):
MPI_Comm comm = MPI_COMM_WORLD; int nprocs; int errorcode; errorcode = MPI_Comm_size( MPI_COMM_WORLD,&nprocs); if (errorcode!=MPI_SUCCESS) { printf("Routine MPI_Comm_size failed! code=%d\n", errorcode); return 1; }However, the error codes are hardly ever useful, and there is not much your program can do to recover from an error. Most people call the routine asMPI_Comm_size( /* parameter ... */ );
For more on error handling, see section 15.2 . -
The first argument is of type
MPI_Comm
. This is not a C
built-in datatype, but it behaves like one. There are many of these
MPI_something
datatypes in MPI. So you can write:
MPI_Comm my_comm = MPI_COMM_WORLD; // using a predefined value MPI_Comm_size( comm, /* remaining parameters */ ); -
Finally, there is a `star' parameter. This means that the
routine wants an address, rather than a value. You would typically write:
MPI_Comm my_comm = MPI_COMM_WORLD; // using a predefined value int nprocs; MPI_Comm_size( comm, &nprocs );
Seeing a `star' parameter usually means either: the routine has an array argument, or: the routine internally sets the value of a variable. The latter is the case here.
1.5.5.2 Fortran
crumb trail: > mpi-started > Language bindings > How to read routine signatures > Fortran
The Fortran specification looks like:
MPI_Comm_size(comm, size, ierror) Type(MPI_Comm), Intent(In) :: comm Integer, Intent(Out) :: size Integer, Optional, Intent(Out) :: ierroror for the Fortran90 legacy mode:
MPI_Comm_size(comm, size, ierror) INTEGER, INTENT(IN) :: comm INTEGER, INTENT(OUT) :: size INTEGER, OPTIONAL, INTENT(OUT) :: ierrorThe syntax of using this routine is close to this specification: you write
Type(MPI_Comm) :: comm = MPI_COMM_WORLD ! legacy: Integer :: comm = MPI_COMM_WORLD Integer :: comm = MPI_COMM_WORLD Integer :: size,ierr CALL MPI_Comm_size( comm, size ) ! without the optional ierr
- Most Fortran routines have the same parameters as the corresponding C routine, except that they all have the error code as final parameter, instead of as a function result. As with C, you can ignore the value of that parameter. Just don't forget it.
- The types of the parameters are given in the specification.
- Where C routines have MPI_Comm and MPI_Request and such parameters, Fortran has INTEGER parameters, or sometimes arrays of integers.
1.5.5.3 Python
crumb trail: > mpi-started > Language bindings > How to read routine signatures > Python
The Python interface to MPI uses classes and objects. Thus, a specification like:
MPI.Comm.Send(self, buf, int dest, int tag=0)should be parsed as follows.
-
First of all, you need the
MPI
class:
from mpi4py import MPI
-
Next, you need a
Comm
object. Often you will use the
predefined communicator
comm = MPI.COMM_WORLD
-
The keyword
self
indicates that the actual routine
Send
is a method of the
Comm
object, so you call:
comm.Send( .... )
-
Parameters that are listed by themselves, such as
buf
, as
positional. Parameters that are listed with a type, such as \n{int
dest} are keyword parameters. Keyword parameters that have a value
specified, such as
int tag=0
are optional, with the default
value indicated. Thus, the typical call for this routine is:
comm.Send(sendbuf,dest=other)
specifying the send buffer as positional parameter, the destination as keyword parameter, and using the default value for the optional tag.
MPI.Request.Waitall(type cls, requests, statuses=None)would be used as
MPI.Request.Waitall(requests)
1.6 Review
crumb trail: > mpi-started > Review
Review What determines the parallelism of an MPI job?
- The size of the cluster you run on.
- The number of cores per cluster node.
- The parameters of the MPI starter ( mpiexec , ibrun ,\ldots)
End of review
Review
T/F: the number of cores of your laptop is the limit of how many MPI
proceses you can start up.
End of review
Review Do the following languages have an object-oriented interface to MPI? In what sense?
- C
- C++
- Fortran2008
- Python
End of review